Cache is King
I previously wrote that the keys to a fast web app are using Ajax, optimizing JavaScript, and better caching.
- Using Ajax reduces network traffic to just a few JSON requests.
- Optimizing JavaScript (downloading scripts asynchronously, grouping DOM modifications, yielding to the UI thread, etc.) allows requests to happen in parallel and makes rendering happen sooner.
- Better caching means many of the web app’s resources are stored locally and don’t require any HTTP requests.
It’s important to understand where the benefits from each technique come into play. Using Ajax, for example, doesn’t make the initial page load time much faster (and often makes it slower if you’re not careful), but subsequent “pages” (user actions) are snappier. Optimizing JavaScript, on the other hand, makes both the first page view and subsequent pages faster. Better caching sits in the middle: The very first visit to a site isn’t faster, but subsequent page views are faster. Also, even after closing their browser the user gets a faster initial page when she returns to your site – so the performance benefit transcends browser sessions.
These web performance optimizations aren’t mutually exclusive – you should do them all! But I (and perhaps you) wonder which has the biggest impact. So I decided to run a test to measure these different factors. I wanted to see the benefits on real websites, so that pointed me to WebPagetest where I could easily do several tests across the Alexa Top 1000 websites. Since there’s no setting to “Ajaxify” a website, I decided instead to focus on time spent on the network. I settled on doing these four tests:
- Baseline – Run the Alexa Top 1000 through WebPagetest using IE9 and a simulated DSL connection speed (1.5 Mbps down, 384 Kbps up, 50ms RTT). Each URL is loaded three times and the median (based on page load time) is the final result. We only look at the “first view” (empty cache) page load.
- Fast Network – Same as Baseline except use a simulated FIOS connection: 20 Mbps down, 5 Mbps up, 4ms RTT.
- No JavaScript – Same as Baseline except use the new “noscript” option to the RESTful API (thanks Pat!). This is the same as choosing the browser option to disable JavaScript. This isn’t a perfect substitute for “optimizing JavaScript” because any HTTP requests that are generated from JavaScript are skipped. On the other hand, any resources inside NOSCRIPT tags are added. We’ll compare the number of HTTP requests later.
- Primed Cache – Same as Baseline except only look at “repeat view”. This test looks at the best case scenario for the benefits of caching given the caching headers in place today. Since not everything is cacheable, some network traffic still occurs.
Which test is going to produce the fastest page load times? Stop for a minute and write down your guess. I thought about it before I started and it turned out I was wrong.
The Results
This chart shows the median and 95th percentile window.onload time for each test. The Baseline median onload time is 7.65 seconds (95th is 24.88). Each of the optimizations make the pages load significantly faster. Here’s how they compare:
- Primed Cache is the fastest test at 3.46 seconds (95th is 12.00).
- Fast Network is second fastest at 4.13 seconds (95th is 13.28).
- No JavaScript comes in third at 4.74 seconds (95th is 15.76).

I was surprised that No JavaScript wasn’t the fastest. Disabling JavaScript removes the blocking behavior that can occur when downloading resources. Even though scripts in IE9 download in parallel with most other resources (see Browserscope) they cause blocking for font files and other edge cases. More importantly, disabling JavaScript reduces the number of requests from the Baseline of 90 requests down to 59, and total transfer size drops from 927 kB to 577 kB.

The improvement from a Fast Network was more than I expected. The number of requests and total transfer size were the same as the Baseline, but the median onload time was 46% faster, from 7.65 seconds down to 4.13 seconds. This shows that network conditions (connection speed and latency) have a significant impact. (No wonder it’s hard to create a fast mobile experience.)
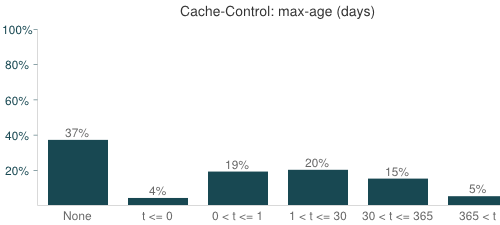
The key to why Primed Cache won is the drop in requests from 90 to 32. There were 58 requests that were read from cache without generating any HTTP traffic. The HTTP Archive max-age chart for the Alexa Top 1000 shows that 59% of requests are configured to be cached (max-age > 0). Many of these have short cache times of 10 minutes or less, but since the “repeat view” is performed immediately these are read from cache – so it truly is a best case scenario. 59% of 90 is 53. The other 5 requests were likely pulled from cache because of heuristic caching.
Although the results were unexpected, I’m pleased that caching turns out to be such a significant (perhaps the most significant) factor in making websites faster. I recently announced my focus on caching. This is an important start – raising awareness about the opportunity that lies right in front of us.
The number of resource requests was reduced by 64% using today’s caching headers, but only because “repeat view” runs immediately. If we had waited one day, 19% of the requests would have been expired generating 17 new If-Modified-Since requests. And it’s likely that some of the 5 requests that benefited from heuristic caching would have generated new requests. Instead we need to move in the other direction making more resources cacheable for longer periods of time. And given the benefits of loading resources quickly we need to investigate ways to prefetch resources before the browser even asks for them.
Kyle Simpson | 11-Oct-12 at 8:29 pm | Permalink |
Excellent post and analysis, Steve.
I think this further reinforces one of the points I’ve made for years about the value of dynamic script loading where you should first concat all your JS into a single file (down from 10-20+ files on average), but THEN split that into 2-3 chunks, and load them dynamically.
I usually point out the value of parallel loading in that scenario, which has been proven many times over (despite the cargo cult “load a single file only” mentality that prevails). But there’s another, and as you point out, MORE important benefit:
** different caching headers **
If you are combining all your JS into a single concat file, you are undoubtedly combining some code which is extremely stable (like a jQuery release which will never ever change) and some (maybe a lot) which is quite volatile (like your UX code you tweak frequently). If you only serve one file, you have to pick one caching length for all that code.
If you split your JS into 2 chunks (the volatile chunk and the stable chunk), you can serve each with different caching length headers. When your UX code updates frequently, over time, repeat users on your site will not have to keep downloading all that stable code over and over again.
I have done these things in production on large sites and I can attest time and again it helps. It helps big time. And it’s nice to see your real numbers research backing that up.
joe vallender | 12-Oct-12 at 8:14 am | Permalink |
totally agree about having at least two aggregated files, kyle.
I’ve found this to be a real necessity for those projects that seem to be perpetually ‘in development’ or with frequent releases
Ali | 13-Oct-12 at 5:16 am | Permalink |
Great work. With regard to AJAX advice, I also personally prefer SPA-style applications over server-rendered resources.
However, there is a school of thought gaining momentum recently – especially in the REST community – that believes SPA-style leads to bad design and slow user experience – main page loads and then it has to start loading all the resources. Twitter’s move for scrapping its SPA has been taken as a proof in the industry.
One of the main problems I have with server-rendered views is that they are composed resources as such very bad for caching.
Watch this space for more controversy!
Laurens | 15-Oct-12 at 2:18 pm | Permalink |
Nice work Steve. There is a flaw in the test though. IE9 does not block the (on)load event if external javascripts are dynamically inserted to the DOM. Not even when an advertisement uses document.write, so yes the impact of no JS seems lower than you would expect. I think the result will be different if you would use Chrome.
In my opinion measuring untill onload within IE does not shape a realistic picture of the real page performance. The stuff that happens after the (on)load (but still belongs to the initial payload) is a blind spot. Would be great if navigation timing could go beyond (on)load.
Steve Souders | 15-Oct-12 at 4:05 pm | Permalink |
@Laurens: That’s a good point. I don’t know what the impact would be. Next time I’ll using Chrome.
Nick Retallack | 17-Oct-12 at 4:01 pm | Permalink |
In your metrics, you never mentioned the Expires header. Doesn’t it serve the same purpose as max-age?
Steve Souders | 18-Oct-12 at 11:34 am | Permalink |
@Nick: It’s fine to use Expires instead of or in addition to max-age. Two advantages of max-age are it’s an absolute # of seconds and thus is not subject to clock skew issues between the client and server, and max-age is part of the Cache-Control header which includes other values which means you can do with one less response header.
dguimbellot | 19-Oct-12 at 12:25 pm | Permalink |
cached items are also stored on the edge as well as local proxies. thus the risk of 1 day cache misses having to go to the max latency server is also lower.
is there some way with ALexa or view across shared google analytics to analyze the age time vs. actual fetch to calculate a best case setting for the user community at large?
Lennie | 20-Oct-12 at 12:55 pm | Permalink |
Steve,
Did you or anyone else test if the small caches on mobile store the files compressed ?
Or is it as bad as on the desktop where Safari for example does not cache compressed ?
I have a hard time finding numbers on that.
I did see numbers on your site and others on how small (and non-persistent) the caches on mobile browsers are and which browsers on the desktop store the data compressed.
But not the combination.
Steve Souders | 20-Oct-12 at 4:37 pm | Permalink |
@dguimbellot: I’ll be announcing a new experiment to measure average time-in-cache. Stay tuned.
@Lennie: I don’t know whether mobile devices stored cached items compressed or uncompressed.