Cache is King
I previously wrote that the keys to a fast web app are using Ajax, optimizing JavaScript, and better caching.
- Using Ajax reduces network traffic to just a few JSON requests.
- Optimizing JavaScript (downloading scripts asynchronously, grouping DOM modifications, yielding to the UI thread, etc.) allows requests to happen in parallel and makes rendering happen sooner.
- Better caching means many of the web app’s resources are stored locally and don’t require any HTTP requests.
It’s important to understand where the benefits from each technique come into play. Using Ajax, for example, doesn’t make the initial page load time much faster (and often makes it slower if you’re not careful), but subsequent “pages” (user actions) are snappier. Optimizing JavaScript, on the other hand, makes both the first page view and subsequent pages faster. Better caching sits in the middle: The very first visit to a site isn’t faster, but subsequent page views are faster. Also, even after closing their browser the user gets a faster initial page when she returns to your site – so the performance benefit transcends browser sessions.
These web performance optimizations aren’t mutually exclusive – you should do them all! But I (and perhaps you) wonder which has the biggest impact. So I decided to run a test to measure these different factors. I wanted to see the benefits on real websites, so that pointed me to WebPagetest where I could easily do several tests across the Alexa Top 1000 websites. Since there’s no setting to “Ajaxify” a website, I decided instead to focus on time spent on the network. I settled on doing these four tests:
- Baseline – Run the Alexa Top 1000 through WebPagetest using IE9 and a simulated DSL connection speed (1.5 Mbps down, 384 Kbps up, 50ms RTT). Each URL is loaded three times and the median (based on page load time) is the final result. We only look at the “first view” (empty cache) page load.
- Fast Network – Same as Baseline except use a simulated FIOS connection: 20 Mbps down, 5 Mbps up, 4ms RTT.
- No JavaScript – Same as Baseline except use the new “noscript” option to the RESTful API (thanks Pat!). This is the same as choosing the browser option to disable JavaScript. This isn’t a perfect substitute for “optimizing JavaScript” because any HTTP requests that are generated from JavaScript are skipped. On the other hand, any resources inside NOSCRIPT tags are added. We’ll compare the number of HTTP requests later.
- Primed Cache – Same as Baseline except only look at “repeat view”. This test looks at the best case scenario for the benefits of caching given the caching headers in place today. Since not everything is cacheable, some network traffic still occurs.
Which test is going to produce the fastest page load times? Stop for a minute and write down your guess. I thought about it before I started and it turned out I was wrong.
The Results
This chart shows the median and 95th percentile window.onload time for each test. The Baseline median onload time is 7.65 seconds (95th is 24.88). Each of the optimizations make the pages load significantly faster. Here’s how they compare:
- Primed Cache is the fastest test at 3.46 seconds (95th is 12.00).
- Fast Network is second fastest at 4.13 seconds (95th is 13.28).
- No JavaScript comes in third at 4.74 seconds (95th is 15.76).

I was surprised that No JavaScript wasn’t the fastest. Disabling JavaScript removes the blocking behavior that can occur when downloading resources. Even though scripts in IE9 download in parallel with most other resources (see Browserscope) they cause blocking for font files and other edge cases. More importantly, disabling JavaScript reduces the number of requests from the Baseline of 90 requests down to 59, and total transfer size drops from 927 kB to 577 kB.

The improvement from a Fast Network was more than I expected. The number of requests and total transfer size were the same as the Baseline, but the median onload time was 46% faster, from 7.65 seconds down to 4.13 seconds. This shows that network conditions (connection speed and latency) have a significant impact. (No wonder it’s hard to create a fast mobile experience.)
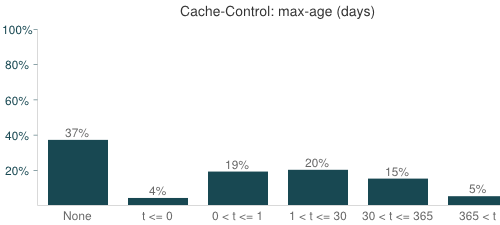
The key to why Primed Cache won is the drop in requests from 90 to 32. There were 58 requests that were read from cache without generating any HTTP traffic. The HTTP Archive max-age chart for the Alexa Top 1000 shows that 59% of requests are configured to be cached (max-age > 0). Many of these have short cache times of 10 minutes or less, but since the “repeat view” is performed immediately these are read from cache – so it truly is a best case scenario. 59% of 90 is 53. The other 5 requests were likely pulled from cache because of heuristic caching.
Although the results were unexpected, I’m pleased that caching turns out to be such a significant (perhaps the most significant) factor in making websites faster. I recently announced my focus on caching. This is an important start – raising awareness about the opportunity that lies right in front of us.
The number of resource requests was reduced by 64% using today’s caching headers, but only because “repeat view” runs immediately. If we had waited one day, 19% of the requests would have been expired generating 17 new If-Modified-Since requests. And it’s likely that some of the 5 requests that benefited from heuristic caching would have generated new requests. Instead we need to move in the other direction making more resources cacheable for longer periods of time. And given the benefits of loading resources quickly we need to investigate ways to prefetch resources before the browser even asks for them.
WebPerfDays: Performance Tools
I just returned from Velocity Europe in London. It was stellar. And totally exhausting! But this post is about the other fantastic web performance event that took place after Velocity: WebPerfDays London.
WebPerfDays is like a day-long web performance meetup event. Aaron Kulick organized the first one last June right after Velocity US. He had the brilliant idea to grab webperfdays.org with the goal of starting a series of events modeled after DevOpsDay. The intent is for other people to organize their own WebPerfDays events. All the resources are meant to be shared – the website, domain, templates, Twitter handle, etc.
Stephen Thair continued the tradition by organizing last week’s WebPerfDays in London. It was held at Facebook’s new London office. They contributed their space on the top floor with beautiful views. (Sorry for the broken sofa.) WebPerfDays is an UNconference, so the agenda was determined by the attendees. I nominated a session on performance tools based on two questions:
What’s your favorite web performance tool?
What tools are missing?
Here are the responses gathered from the attendees:
Favorite Performance Tool:
- WebPagetest
- Cuzillion
- Chrome Dev Tools
- Speed Tracer
- Performance Analyzer from Site Confidence (pay)
- SPOF-O-Matic, 3PO for YSlow
- Wireshark
- PageSpeed, YSlow
- dynaTrace Ajax Edition and SpeedoftheWeb
- HTTP Archive
- Critical Path Explorer – part of PageSpeed Insights
- PhantomJS
- mobile remote debugging: Weinre, jsconsole.com, Opera Dragonfly, Chrome for Android
- Apache Bench (ab)
- Show Slow
- Browserscope
- Tilt, DOM Monster
- Mobileperf Bookmarklet
- chrome://net-internals
- Redbot
- SpriteMe
- Boomerang, Episodes
- wget, telnet
- Wappalyzer
- Netalyzer
- Shunra NetworkCatcher Express
- Packet Flight
- Fiddler, Charles
- CSS Lint, JSLint
- GTMetrix
Updates:
- Torbit Insight
- Grunt.js
- sitespeed.io
- SSL Server Test
- SPDY Indicator (Firefox, Chrome), SPDYCheck.org
- KITE, MITE
- Compass (CSS)
- Soke, Seige, Tsung (load testing)
- SpeedCheckr
Missing Tools:
- When analyzing a website need a tool that calculates the average delta between last-modified date and today and compare that to the expiration time. The goal is to indicate to the web developer if the expiration window is commensurate with the resource change rate. This could be part of PageSpeed, YSlow, and HTTP Archive, for example.
- Automated tool that determines if a site is using a blocking snippet when an async snippet is available. For example, PageSpeed does this but only for Google Analytics.
- Tools that diagnose the root cause for rendering being delayed.
- Easier visibility into DNS TTLs, e.g., built into Chrome Dev Tools and WebPagetest.
- Backend tool that crawls file directories and optimizes images. Candidate tools: Yeoman, Wesley.
- Nav Timing in (mobile) Safari.
- Better tools for detecting and diagnosing memory leaks.
- Web timing specs for time spent on JavaScript, CSS, reflow, etc. (available in JavaScript).
- Tools to visualize and modify Web Storage (localStorage, app cache, etc.).
- Tools to visualize and clear DNS cache.
- A version of JSLint focused on performance suggestions.
- A tool that can diff two HAR files.
Updates:
- in-browser devtools letting you drill into each resource fetched or cached, listing the full set of reasons (down to the combination of http headers at play in the current and, as applicable, a prior request) for why that resource was or wasn’t loaded from the cache, when it would get evicted from cache and why: https://bugs.webkit.org/show_bug.cgi?id=83986
This was stream of consciousness from the audience. It’s not an exhaustive list. Do you have a favorite web performance tool that’s not listed? Or a performance analysis need without a tool to help? If so, add a comment below. And consider organizing WebPerfDays in your area. Aaron, Stephen, and I would be happy to help.
Async Scripts – Cached?
I want to re-run the real user cache experiment that Tenni Theurer and I ran back in 2007. I’m designing the experiment now and will share that design in this blog when it’s well-baked. One change is I’d like to use an external script as the cached response that is tested. Another change is I want the experiment to be a snippet that any website can embed. That allows me to crowdsource results from websites with a wider range of session behaviors, user profiles, browsers, etc.
Since I’ll be asking websites to embed this 3rd party script, it’s important that it not harm performance and avoid frontend SPOF. I’ll do this using JavaScript to dynamically request the external script using the typical createElement-insertBefore pattern:
var newscript = document.createElement("script");
newscript.async = true;
newscript.src = document.location.protocol + "//NOTstevesouders.com/testscript.js";
var s0 = document.getElementsByTagName('script')[0];
s0.parentNode.insertBefore(newscript, s0);
But I wondered: Does loading an external script this way affect caching behavior?
I’ve been using this pattern for years and know that caching headers for dynamically-loaded scripts are respected in all the major desktop & mobile browsers, but what about other browsers? To answer this question I created a Browserscope user test last week. The Caching Async Scripts test page loads a script dynamically. The script has a far future expiration date so on the next page it should be read from cache. This is tested by measuring the script’s load time – normally it takes 6 seconds to load so if it’s far less than that it must have been read from cache.
I tweeted the test’s URL asking people to run the test. Thanks to everyone who ran it! The crowdsourced Browserscope results show data for over sixty browsers including Blackberry, Epiphany, and PlayStation. Happily, and surprisingly, it shows that every browser honors caching headers for scripts loaded dynamically. That’s great news in general, and with regard to re-running the cache experiment means that I can feel comfortable using this pattern to load the cached script while avoiding frontend SPOF.
Preferred Caching
In Clearing Browser Data I mentioned Internet Explorer’s “Preserve Favorites website data” option. It first appeared in Internet Explorer 8’s Delete Browsing History dialog:

This is a great idea. I advocated this to all browser makers at Velocity 2009 under the name “preferred caching”. My anecdotal experience is that even though I visit a website regularly, its static resources aren’t always in my cache. This could be explained by the resources not having the proper caching headers, but I’ve seen this happen for websites that I know use far future expiration dates. The browser disk cache is shared across all websites, therefore one website with lots of big resources can push another website’s resources from cache. Even though I have preferred websites, there’s no way for me to guarantee their resources are given a higher priority when it comes to caching. And yet:
A key factor for getting web apps to perform like desktop and native apps is ensuring that their static content is immediately available on the client.
A web app (especially a mobile web app) can’t startup quickly if it has to download its images, scripts, and stylesheets over the Internet. It can’t even afford to do lightweight Conditional GET requests to verify resource freshness. A fast web app has to have all its static content stored locally, ready to be served as soon as the user needs it.
Application cache and localStorage are ways to solve this problem, but users only see the benefits if/when their preferred websites adopt these new(ish) technologies. And there’s no guarantee a favorite website will ever make the necessary changes. Application cache is hard to work with and has lots of gotchas. Some browser makers warn that localStorage is bad for performance.
The beauty of “Preserve Favorites website data” is that the user can opt in without having to wait for the website owner to get on board. This doesn’t solve all the problems: if a website starts using new resources then the user will have to undergo the delay of waiting for them to download. But at least the user knows that the unchanged resources for their preferred websites will always be loaded without having to incur network delays.
Let’s play with it
I found very little documentation on “Preserve Favorites website data”. Perhaps it’s self-explanatory, but I find that nothing works as expected when it comes to the Web. So I did a little testing. I used the Clear Browser test to explore what actually was and wasn’t cleared. The first step was to save https://stevesouders.com/ as a Favorite. I then ran the test withOUT selecting “Preserve Favorites website data” – everything was deleted as expected:
- IE 8 & 9: cookies & disk cache ARE cleared (appcache isn’t supported; localStorage isn’t cleared likely due to a UI bug)
- IE 10: cookies, disk cache, & appcache ARE cleared (localStorage isn’t cleared likely due to a UI bug)
Then I ran the test again but this time I DID select “Preserve Favorites website data” (which tells IE to NOT clear anything for stevesouders.com) and saw just one surprise for IE 10:
- IE 8 & 9: cookies & disk cache ARE NOT cleared (correct)
- IE 10: cookies & disk cache ARE NOT cleared (correct), but appcache IS cleared (unexpected)
Why would appcache get cleared for a Favorite site when “Preserve Favorites website data” is selected? That seems like a bug. Regardless, for more popular persistent data (cookies & disk cache) this setting leaves them in the cache allowing for a faster startup next time the user visits their preferred sites.
It’s likely to be a long time before we see other browsers adopt this feature. To figure out whether they should it’d be helpful to get your answers to these two questions:
- How many of you using Internet Explorer select “Preserve Favorites website data” when you clear your cache?
- For non-IE users, would you use this feature if it was available in your browser?
Clearing Browser Data
In Keys to a Fast Web App I listed caching as a big performance win. I’m going to focus on caching for the next few months. The first step is a study I launched a few days ago called the Clear Browser Experiment. Before trying to measure the frequency and benefits of caching, I wanted to start by gauging what happens when users clear their cache. In addition to the browser disk cache, I opened this up to include other kinds of persistent data: cookies, localStorage, and application cache. (I didn’t include indexedDB because it’s less prevalent.)
Experiment Setup
The test starts by going to the Save Stuff page. That page does four things:
- Sets a persistent cookie called “cachetest”. The cookie is created using JavaScript.
- Tests
window.localStorageto see if localStorage is supported. If so, saves a value to localStorage with the key “cachetest”. - Tests
window.applicationCacheto see if appcache is supported. If so, loads an iframe that uses appcache. The iframe’s manifest file has a fallback section containing “iframe404.js iframe.js”. Since iframe404.js doesn’t exist, appcache should instead load iframe.js which defines the global variableiframejsNow. - Loads an image that takes 5 seconds to return. The image is cacheable for 30 days.
After this data is saved to the browser, the user is prompted to clear their browser and proceed to the Check Cache page. This page checks to see if the previous items still exist:
- Looks for the cookie called “cachetest”.
- Checks localStorage for the key “cachetest”.
- Loads the iframe again. The iframe’s onload handler checks ifÂ
iframejsNowis defined in which case appcache was not cleared. - Loads the same 5-second image again. The image’s onload handler checks if it takes more than 5 seconds to return, in which case disk cache was cleared.
My Results
I created a Browserscope user test to store the results. (If you haven’t used this feature you should definitely check it out. Jason Grigsby is glad he did.) This test is different from my other tests because it requires the user to do an action. Because of this I ran the test on various browsers to create a “ground truth” table of results. Green and “1” indicate the data was cleared successfully while red and “0” indicate it wasn’t. Blank means the feature wasn’t supported.

The results vary but are actually more consistent than I expected. Some observations:
- Chrome 21 doesn’t clear localStorage. This is perhaps an aberrant result due to the structure of the test. Chrome 21 clears localStorage but does not clear it from memory in the current tab. If you switch tabs or restart Chrome the result is cleared. Nevertheless, it would be better to clear it from memory as well. The Chrome team has already fixed this bug as evidenced by the crowdsourced results for Chrome 23.0.1259 and later.
- Firefox 3.6 doesn’t clear disk cache. The disk cache issue is similar to Chrome 21’s story: the image is cleared from disk cache, but not from memory cache. Ideally both would be cleared and the Firefox team fixed this bug back in 2010.
- IE 6-7 don’t support appcache nor localStorage.
- IE 8-9 don’t support appcache.
- Firefox 3.6, IE 8-9, and Safari 5.0.5 don’t clear localStorage. My hypothesis for this result is that there is no UI attached to localStorage. See the following section on Browser UIs for screenshots from these browsers.
Browser UIs
Before looking at the crowdsourced results, it’s important to see what kind of challenges the browser UI presents to clearing data. This is also a handy, although lengthy, guide to clearing data for various browsers. (These screenshots and menu selections were gathered from both Mac and Windows so you might see something different.)
Chrome
Clicking on the wrench icon -> History -> Clear all browsing data… in Chrome 21 displays this dialog. Checking “Empty the cache” clears the disk cache, and “Delete cookies and other site and plug-in data” clears cookies, localStorage, and appcache.

Firefox
To clear Firefox 3.6 click on Tools -> Clear Recent History… and check Cookies and Cache. To be extra aggressive I also checked Site Preferences, but none of these checkboxes cause localStorage to be cleared.

Firefox 12 fixed this issue by adding a checkbox for Offline Website Data. Firefox 15 has the same choices. As a result localStorage is cleared successfully.

Internet Explorer
It’s a bit more work to clear IE 6. Clicking on Tools -> Internet Options… -> General presents two buttons: Delete Cookies… and Delete Files… Both need to be selected and confirmed to clear the browser. There’s an option to “Delete all offline content” but since appcache and localStorage aren’t supported this isn’t relevant to this experiment.

Clearing IE 7 is done by going to Tools -> Delete Browsing History… There are still separate buttons for deleting files and deleting cookies, but there’s also a “Delete all…” button to accomplish everything in one action.

The clearing UI for IE 8 is reached via Tools -> Internet Options -> General -> Delete… It has one additional checkbox for clearing data compared to IE 7: “InPrivate Filtering data”. (It also has “Preserve Favorites website data” which I’ll discuss in a future post.) LocalStorage is supported in IE 8, but according to the results it’s not cleared and now we see a likely explanation: there’s no checkbox for explicitly clearing offline web data (as there is in Firefox 12+).
IE 9’s clearing UI changes once again. “Download History” is added, and “InPrivate Filtering data” is replaced with “ActiveX Filtering and Tracking Protection data”. Similar to IE 8, localStorage is supported in IE 9, but according to the results it’s not cleared and the likely explanation is that there is not a checkbox for explicitly clearing offline web data (as there is in Firefox 12+).

iPhone
The iPhone (not surprisingly) has the simplest UI for clearing browser data. Going through Settings -> Safari we find a single button: “Clear Cookies and Data”. Test results show that this clears cookies, localStorage, appcache, and disk cache. It’s hard to run my test on the iPhone because you have to leave the browser to get to Settings, so when you return to the browser the test page has been cleared. I solve this by typing in the URL for the next page in the test: https://stevesouders.com/tests/clearbrowser/check.php.

Opera
Opera has the most granularity in what to delete. In Opera 12 going to Tools -> Delete Private Data… displays a dialog box. The key checkboxes for this test are “Delete all cookies”, “Delete entire cache”, and “Delete persistent storage”. There’s a lot to choose from but it’s all in one dialog.

Safari
In Safari 5.0.5 going to gear icon -> Reset Safari… (on Windows) displays a dialog box with many choices. None of them address “offline data” explicitly which is likely why the results show that localStorage is not cleared. (“Clear history” has no effect – I just tried it to see if it would clear localStorage.)

Safari 5.1.7 was confusing for me. At first I chose Safari -> Empty cache… (on Mac) but realized this only affected disk cache. I also saw Safari -> Reset Safari… but this only had “Remove all website data” which seemed too vague and broad. I went searching for more clearing options and found Safari -> Preferences… -> Privacy with a button to “Remove All Website Data…” but this also had no granularity of what to clear. This one button did successfully clear cookies, localStorage, appcache, and disk cache.

Crowdsourced Results
The beauty of Browserscope user tests is that you can crowdsource results. This allows you to gather results for browsers and devices that you don’t have access to. The crowdsourced results for this experiment include ~100 different browsers including webOS, Blackberry, and RockMelt. I extracted results for the same major browsers shown in the previous table.

In writing up the experiment I intentionally used the generic wording “clear browser” in an attempt to see what users would select without prompting. The crowdsourced results match my personal results fairly closely. Since this test required users to take an action without a way to confirm that they actually did try to clear their cache, I extended the table to show the percentage of tests that reflect the majority result.
One difference between my results and the crowdsourced results is iPhone – I think this is due to the fact that clearing the cache requires leaving the browser thus disrupting the experiment. The other main difference is Safari 5. The sample size is small so we shouldn’t draw strong conclusions. It’s possible that having multiple paths for clearing data caused confusion.
The complexity and lack of consistency in UIs for clearing data could be a cause for these less-than-unanimous results. Chrome 21 and Firefox 15 both have a fair number of tests (154 and 46), and yet some of the winning results are only seen 50% or 68% of the time. Firefox might be a special case because it prompts before saving information to localStorage. And this test might be affected by private browsing such as Chrome’s incognito mode. Finally, it’s possible test takers didn’t want to clear their cache but still saved their results to Browserscope.
There are many possible explanations for the varied crowdsourced results, but reviewing the Browser UIs section shows that knowing how to clear browser data varies significantly across browsers, and often changes from one version of a browser to the next. There’s a need for more consistent UI in this regard. What would a consistent UI look like? The simple iPhone UI (a single button) makes it easier to clear everything, but is that what users want and need? I often want to clear my disk cache, but less frequently choose to clear all my cookies. At a minimum, users need a way to clear their browser data in all browsers, which currently isn’t possible.
Keys to a Fast Web App
I recently tweeted that the keys to a faster web app are Ajax architecture, JavaScript, and caching. This statement is based on my experience – I don’t have hard data on the contribution each makes and the savings that could be had. But let me comment on each one.
Ajax architecture – Web 1.0 with a page reload on every user action is not the right choice. Yanking the page out from under the user and reloading resources that haven’t changed produces a frustrating user experience. Maintaining a constant UI chrome with a Web 2.0 app is more seamless, and Ajax allows us to perform content updates via lightweight data API requests and clientside JavaScript resulting in a web app that is smooth and fast (when done correctly).
JavaScript – JavaScript is a major long pole in the web performance tent, but just a few years ago it was even worse. Do you remember?! It used to be that loading a script blocked the HTML parser and all other downloads in the page. Scripts were downloaded one-at-a-time! In 2009 IE8 became the first browser to support parallel script loading. Firefox 3.5, Chrome 2, and Safari 4 soon followed, and more recently Opera 12 got on the bus. (Parallel script loading is the single, most important improvement to web performance IMO.) In addition to loading scripts, the speed of the JavaScript engines themselves has increased significantly. So we’re much better off than we were a few years ago. But when I do performance deep dives on major websites JavaScript is still the most frequent reason for slow pages, especially slow rendering. This is due to several factors. JavaScript payloads have increased to ~200K. Browsers still have blocking behavior around JavaScript, for example, a stylesheet followed by an inline script can block subsequent downloads in some browsers. And until we have wider support for progressive enhancement, many webpages are blank while waiting for a heavy JavaScript payload to be downloaded, parsed, and executed.
Caching – Better caching doesn’t make websites faster for first time users. But in the context of web apps we’re talking about users who are involved in a longer session and who are likely to come back to use this web app again. In the voyage to create web app experiences that rival those of desktop and native, caching is a key ingredient. Caching frustrates me. Website owners don’t use caching as much as they should. 58% of responses don’t have caching headers, and 89% are cacheable for less than a month even though 38% of those don’t change. Browser caches are too small and their purging algorithms need updating. We have localStorage with a super simple API, but browser makers warn that it’s bad for performance. Application cache is a heavier solution, but it’s hard to work with (see also the great presentation from Jake Archibald).
I’m obsessed with caching. It’s the biggest missed opportunity and so I’m going to spend the next few months focused on caching. Analyzing caching is difficult. In the lab it’s hard (and time consuming) to test filling and clearing the cache. There’s no caching API that makes it easy to manipulate and measure.
Testing caching in the lab is informative, but it’s more important for web devs and browser makers to understand how caching works for real users. It’s been 5 years since Tenni Theurer and I ran the seminal experiment to measure browser cache usage. That study showed that 20% of page views were performed with an empty cache, but more surprisingly 40-60% of daily users had at least one empty cache page view. I’ll definitely re-run this experiment.
I’ve started my caching focus by launching a test to measure what happens when users clear their cache. It’s interesting how browsers differ in their UIs for caching. They’re neither intuitive nor consistent. I would appreciate your help in generating data. Please run the experiment and contribute your results. You can find the experiment here:
I’ll write up the results this weekend. See you Monday.
High Performance everywhere
I started writing High Performance Web Sites in 2006. I got the idea for the title from High Performance MySQL by Jeremy Zawodny. I had lunch with Jeremy before starting my book and asked if it was okay to borrow the “High Performance” moniker, to which he immediately agreed. Jeremy also gave me advice on becoming an author, including an introduction to Andy Oram, the fantastic editor for both Jeremy and my books.
I suggested to O’Reilly that they create a series of “High Performance” computer programming books. Although this wasn’t adopted explicitly, there have been several O’Reilly books that use this naming convention:
- High Performance Computing – 1998(!)
- High Performance MySQL – 2004
- High Performance Linux Clusters – 2004
- High Performance Web Sites – 2007
- High Performance Python – 2009
- High Performance JavaScript – 2010
I’d love to see other High Performance topics including mobile, PHP, node.js, CSS, video, and graphics.
The point is: I think about “High Performance” a lot.
During my summer travels I’ve noticed the use of “High Performance” is getting wider adoption. This first struck me in an Accenture billboard at the airport. Accenture has an entire ad campaign based on the slogan “High Performance. Delivered.”. They even have TV commercials with Tiger Woods, reef predators, triathlons, and analytics.

On the plane I saw an ad in Stanford Magazine for the Graduate School of Business, “Turn High Potential into High Performance”. The ad is for an executive leadership program called Analysis to Action highlighting the need for critical analytical thinking tools.

Given that we’re in the middle of the Summer Olympics the most exciting High Performance reference was in Wired’s article, One One-Hundredth of a Second Faster: Building Better Olympic Athletes. The article itself is intriguing, discussing the role of technology in athletic competition. What really caught my eye was the mention of two people with the title of Director of High Performance:
- Andy Walshe, former US Ski Team sports science director, is Red Bull’s Director of High Performance. (Red Bull sponsors Lolo Jones to the tune of 22 scientists and technicians with 40 motion-capture cameras.)
- Peter Vint is Director of High Performance for the US Olympic Committee.

Given that Velocity Europe 2012 is being held in London (Oct 2-4) I’m trying to contact Andy and Peter to see if they’d like to deliver a keynote address. (If you know either of them please contact me to help make an introduction.) Although athletic performance and web performance are different disciplines, they have in common the process of defining a success function, gathering metrics, and analyzing data to identify best practices for optimizing performance. In both worlds hundredths of a second can make the difference between success and failure.
Self-updating scripts
- The previous code had a race condition when
beacon.jscalleddocument.body.appendChildbefore BODY existed. This was fixed. - Some users reported the
update.phpiframe was opened in a new tab in IE8. I can’t repro this bug but am investigating.
Analyzing your site using Page Speed or YSlow often produces lower scores than you might expect due to 3rd party resources with short cache times. 3rd party snippet owners use short cache times so that users receive updates in a timely fashion, even if this means slowing down the site owner’s page.
Stoyan and I were discussing this and wondered if there was a way to have longer cache times and update resources when necessary. We came up with a solution. It’s simple and reliable. Adopting this pattern will reduce unnecessary HTTP requests resulting in faster pages and happier users, as well as better Page Speed and YSlow scores.
Long cache & revving URLs
Caching is an important best practice for making websites load faster. (If you’re already familiar with caching and 304s you may want to skip to the self-updating section.) Caching is easily achieved by giving resources an expiration date far in the future using the Cache-Control response header. For example, this tells the browser that the response can be cached for 1 year:
Cache-Control: max-age=31536000
But what happens if you make changes to the resource before the year is over? Users who have the old version in their cache won’t get the new version until the resource expires, meaning it would take 1 year to update all users. The simple answer is for the developer to change the resource’s URL. Often this is done by adding a “fingerprint” to the path, such as the source control version number, file timestamp, or checksum. Here’s an example for a script from Facebook:
http://static.ak.fbcdn.net/rsrc.php/v1/yx/r/N-kcJF3mlg6.js
It’s likely that if you compare the resource URLs for major websites over time you’ll see these fingerprints changing with each release. Using the HTTP Archive we see how the URL changes for Facebook’s main script:
http://static.ak.fbcdn.net/rsrc.php/v1/y2/r/UVaDehc7DST.js(March 1)http://static.ak.fbcdn.net/rsrc.php/v1/y-/r/Oet3o2R_9MQ.js(March 15)http://static.ak.fbcdn.net/rsrc.php/v1/yS/r/B-e2tX_mUXZ.js(April 1)http://static.ak.fbcdn.net/rsrc.php/v1/yx/r/N-kcJF3mlg6.js(April 15)
Facebook sets a 1 year cache time for this script, so when they make changes they rev the URL to make sure all users get the new version immediately. Setting long cache times and revving the URL is a common solution for websites focused on performance. Unfortunately, this isn’t possible when it comes to 3rd party snippets.
Snippets don’t rev
Revving a resource’s URL is an easy solution for getting updates to the user when it comes to the website’s own resources. The website owner knows when there’s an update and since they own the web page they can change the resource URL.
3rd party snippets are a different story. In most cases, 3rd party snippets contain the URL for a bootstrap script. For example, here’s the Tweet Button snippet:
<a href="https://twitter.com/share" class="twitter-share-button"
data-lang="en">Tweet</a>
<script>
!function(d,s,id){
var js,fjs=d.getElementsByTagName(s)[0];
if(!d.getElementById(id)){
js=d.createElement(s); js.id=id;
js.src="//platform.twitter.com/widgets.js";
fjs.parentNode.insertBefore(js,fjs);
}}(document,"script","twitter-wjs");
</script>
Website owners paste this snippet code into their pages. In the event of an emergency update, the Twitter team can’t rev the widgets.js URL because they don’t have access to change all the web pages containing this snippet. Notifying all the website owners to update the snippet isn’t an option, either. Since there’s no way to rev the URL, bootstrap scripts typically have a short cache time to ensure users get updates quickly. Twitter’s widgets.js is cacheable for 30 minutes, Facebook’s all.js is cacheable for 15 minutes, and Google Analytics’ ga.js is cacheable for 2 hours. This is much shorter than the recommended practice of setting the expiration date a month or more in the future.
Conditional GETs hurt performance
Unfortunately, these short cache times for bootstrap scripts have a negative impact on web performance. When the snippet’s resource is requested after the cache time has expired, instead of reading the resource from cache the browser has to issue a Conditional GET request (containing the If-Modified-Since and If-None-Match request headers). Even if the response is a simple 304 Not Modified with no response body, the time it takes to complete that roundtrip impacts the user experience. That impact varies depending on whether the bootstrap script is loaded in the normal way vs. asynchronously.
Loading scripts the “normal way” means using HTML: <script src="..."></script>. Scripts loaded this way have several negative impacts: they block all subsequent DOM elements from rendering, and in older browsers they block subsequent resources from being downloaded. These negative impacts also happen when the browser makes a Conditional GET request for a bootstrap script with a short cache time.
If the snippet is an async script, as is the case for widgets.js, the negative impact is reduced. In this case the main drawback impacts the widget itself – it isn’t rendered until the response to the Conditional GET is received. This is disconcerting to users because they see these async widgets popping up in the page after the surrounding content has already rendered.
Increasing the bootstrap script’s cache time reduces the number of Conditional GET requests which in turn avoids these negative impacts on the user experience. But how can we increase the cache time and still get updates to the user in a timely fashion without the ability to rev the URL?
Self-updating bootstrap scripts
A bootstrap script is defined as a 3rd party script with a hardwired URL that can’t be changed. We want to give these scripts long cache times so they don’t slow down the page, but we also want the cached version to get updated when there’s a change. There are two main problems to solve: notifying the browser when there’s an update, and replacing the cached bootstrap script with the new version.
update notification: Here we make the assumption that the snippet is making some subsequent request to the 3rd party server for dynamic data, to send a beacon, etc. We piggyback on this. In the case of the Tweet Button, there are four requests to the server: one for an iframe HTML document, one for JSON containing the tweet count, and two 1×1 image beacons (presumably for logging). Any one of these could be used to trigger an update. The key is that the bootstrap script must contain a version number. That version number is then passed back to the snippet server in order for it to detect if an update is warranted.
replacing the cached bootstrap script: This is the trickier part. If we give the bootstrap script a longer cache time (which is the whole point of this exercise), we have to somehow overwrite that cached resource even though it’s not yet expired. We could dynamically re-request the bootstrap script URL, but it’ll just be read from cache. We could rev the URL by adding a querystring, but that won’t overwrite the cached version with the hardwired URL referenced in the snippet. We could do an XHR and modify the caching headers using setRequestHeader, but that doesn’t work across all browsers.
Stoyan struck on the idea of dynamically creating an iframe that contains the bootstrap script, and then reloading that iframe. When the iframe is reloaded it’ll generate a Conditional GET request for the bootstrap script (even though the bootstrap script is cached and still fresh), and the server will respond with the updated bootstrap script which overwrites the old one in the browser’s cache. We’ve achieved both goals: a longer cache time while preserving the ability to receive updates when needed. And we’ve replaced numerous Conditional GET requests (every 30 minutes in the case of widgets.js) with only one Conditional GET request when the bootstrap script is actually modified.
An example
Take a look at this Self-updating Scripts example modeled after Google Analytics. This example contains four pages.
page 1: The first page loads the example snippet containing bootstrap.js:
(function() {
var s1 = document.createElement('script');
s1.async = true;
s1.src = 'http://souders.org/tests/selfupdating/bootstrap.js';
var s0 = document.getElementsByTagName('script')[0];
s0.parentNode.insertBefore(s1, s0);
})();
Note that the example is hosted on stevesouders.com but the snippet is served from souders.org. This shows that the technique works for 3rd party snippets served from a different domain. At this point your browser cache contains a copy of bootstrap.js which is cacheable for 1 week and contains a “version number” (really just a timestamp). The version (timestamp) of bootstrap.js is shown in the page, for example, 16:23:53. A side effect of bootstrap.js is that it sends a beacon (beacon.js) back to the snippet server. For now the beacon returns an empty response (204 No Content).
page 2: The second page just loads the snippet again to confirm we’re using the cache. This time bootstrap.js is read from cache, so the timestamp should be the same, e.g., 16:23:53. A beacon is sent but again the response is empty.
page 3: Here’s where the magic happens. Once again bootstrap.js is read from cache (so you should see the same version timestamp again). But this time when it sends the beacon the server returns a notification that there’s an update. This is done by returning some JavaScript inside beacon.js:
(function() {
var doUpdate = function() {
if ( "undefined" === typeof(document.body) || !document.body ) {
setTimeout(doUpdate, 500);
}
else {
var iframe1 = document.createElement("iframe");
iframe1.style.display = "none";
iframe1.src = "http://souders.org/tests/selfupdating/update.php?v=[ver #]";
document.body.appendChild(iframe1);
}
};
doUpdate();
})();
The iframe src points to update.php:
<html>
<head>
<script src="http://souders.org/tests/selfupdating/bootstrap.js"></script>
</head>
<body>
<script>
if (location.hash === '') {
location.hash = "check";
location.reload(true);
}
</script>
</body>
</html>
The two key pieces of update.php are a reference to bootstrap.js and the code to reload the iframe. The location hash property is assigned a string to avoid reloading infinitely. The best way to understand the sequence is to look at the waterfall chart.

This page (newver.php) reads bootstrap.js from cache (1). The beacon.js response contains JavaScript that loads update.php in an iframe and reads bootstrap.js from cache (2). But when update.php is reloaded it issues a request for bootstrap.js (3) which returns the updated version and overwrites the old version in the browser’s cache. Voilà !
page 4: The last page loads the snippet once again, but this time it reads the updated version from the cache, as indicated by the newer version timestamp , e.g., 16:24:17.
Observations & adoption
One observation about this approach is the updated version is used the next time the user visits a page that needs the resource (similar to the way app cache works). We saw this in page 3 where the old version of bootstrap.js was used in the snippet and the new version was downloaded afterward. With the current typical behavior of short cache times and many Conditional GET requests the new version is used immediately. However, it’s also true with the old approach that if an update occurs while a user is in the middle of a workflow, the user won’t get the new version for 30 minutes or 2 hours (or whatever the short cache time is). Whereas with the new approach the user would get the update as soon as it’s available.
It would be useful to do a study about whether this approach increases or decreases the number of beacons with an outdated bootstrap script. Another option is to always check for an update. This would be done by having the bootstrap script append and reload the update.php iframe when it’s done. The downside is this would greatly increase the number of Conditional GET requests. The plus side is the 3rd party snippet owner doesn’t have to deal with the version number logic.
An exciting opportunity with this new approach is to treat update.php as a manifest list. It can reference bootstrap.js as well as any other resources that have long cache times but need to be overwritten in the browser’s cache. It should be noted that update.php doesn’t need to be a dynamic page – it can be a static page with a far future expiration date. Also, the list of resources can be altered to reflect only the resources that need to be updated (based on the version number received).
A nice aspect of this approach is that existing snippets don’t need to change. All of the changes necessary to adopt this self-updating behavior are on the snippet owner’s side:
- Add a version number to the bootstrap script.
- Pass back the version number to the snippet server via some other request that can return JavaScript. (Beacons work – they don’t have to be 1×1 transparent images.)
- Modify that request handler to return JavaScript that creates a dynamic iframe when the version is out-of-date.
- Add an
update.phppage that includes the bootstrap script (and other resources you want to bust out of cache). - Increase the cache time for the bootstrap script! 10 years would be great, but going from 30 minutes to 1 week is also a huge improvement.
If you own a snippet I encourage you to consider this self-updating approach for your bootstrap scripts. It’ll produce faster snippets, a better experience for your users, and fewer requests to your server.
Web First for Mobile
My mobile performance research focuses on mobile web. I don’t analyze native apps. Why? I believe in the openness of the Web. I don’t like being forced to use a proprietary technology stack. I don’t like signing legal documents. I don’t like having to be approved by someone. Although I don’t write commercial apps, I don’t want the people who follow my work to have to pay a share of their revenue to a gatekeeper.
I also understand that it’s important for many people to build native apps, especially if they’re doing something like games that require the performance and device APIs that might only be available to native apps (right now). This is not a blog post about whether you should build a mobile web app OR a native app. This blog post is about building your web app first. You might eventually end up with both a web app AND a native app. Regardless, your mobile web presence is the place to start.
This prioritization of mobile web presence before native apps crystalized for me last week at Mobilism. Three speakers, James Pearce, Jason Grigsby, and Scott Jenson highlighted factors for why building for the mobile web should come before native apps.
First off is this slide from James Pearce’s talk. It shows that Facebook’s unique users from mobile web browsers is more than those from their native apps combined. This might not hold true for all companies, but it does show that the web browser can be, and in some cases is, the preferred client on mobile, and certainly lowers the barriers allowing access to a wider audience.

This leads to the second point, this time from Jason Grigsby. Jason actually spoke about TVs at Mobilism (huh?), but I recalled him saying “URLs don’t open apps” when I hosted Jason at Google for a tech talk. People frequently communicate using URLs – in their tweets, emails, bookmarks, etc. And these URLs don’t open apps. So it’s critical that companies ensure they have a web presence that works on mobile.
Jason highlights the need for a mobile web presence with examples including this one from Chanel. This first screen shot shows Chanel’s native app. It’s a good looking UI and we can be assured that Chanel devoted significant resources to build and ship this.

I’m not big on perfume, so I might be biased, but it strikes me that people interested in Chanel might not start by searching the app store. I can see Chanel fans searching Google Maps on their phone for the nearest Chanel store. Or doing a web search for “Chanel” to find a list of store locations on the main website. But when the mobile user navigates to the Chanel site they’ll be sorely disappointed with what they find:

To be fair, that was Chanel’s old website that relied on Flash. Here’s their website today:

The current website is better than a broken Flash object, but this mobile web page falls far short when compared to Chanel’s native app. This is where I see Jason’s point: Many if not most mobile users engage with a company through their website, and URLs don’t open apps. So it’s important to provide an engaging web presence for mobile users.
The third point is from Scott Jenson’s talk at Mobilism where he discusses “just-in-time interaction” – a world where my mobile device allows me to interact with the environment around me: stores, bus stops, and even movie posters.

But this highly interactive experience doesn’t work with native apps. Here’s an excerpt from his related blog post that explains why:
There is no way that I’m going to be able to or even desire to try this type of just-in-time interaction with our current application model today. The energy involved in finding, downloading, using, and most importantly, throwing away an app is just far too great.
While native apps present too much of a hurdle for easy interaction on mobile devices to ubiquitous services, the Web is perfect for that.
My final data point is from the article Why Publishers Don’t Like Apps lamenting the trials and tribulations of building native apps in the world of publishing. Besides the technological challenges, publishers run a business trying to sell articles and issues for money. But after entering the native app market they found the margins were too small:
Apple demanded a 30 percent vigorish on all single-copy sales through its iTunes store. Profit margins in single-copy sales are thinner than 30 percent; publishers were thus paying Apple to move issues.
I’m not saying you shouldn’t build native apps. And I don’t want to have yet-another-debate about web vs. native. I simply want to suggest that you start creating your mobile presence as a web presence. That’s where users are most likely to find you, and you want to give them a good experience when they do.
Don’t docwrite scripts
In yesterday’s blog post, Making the HTTP Archive faster, one of the biggest speedups came from not using a script loader. It turns out that script loader was using document.write to load scripts dynamically. I wrote about the document.write technique in Loading Script Without Blocking back in April 2009, as well as in Even Faster Web Sites (chapter 4). It looks something like this:
document.write('<script src="' + src + '" type="text/javascript"><\/script>'):
The problem with document.write for script loading is:
- Every DOM element below the inserted script is blocked from rendering until the script is done downloading (example).
- It blocks other dynamic scripts (example). One exception is if multiple scripts are inserted usingÂ
document.writewithin the same SCRIPT block (example).
Because the script loader was using document.write, the page I was optimizing rendered late and other async scripts in the page took longer to download. I removed the script loader and instead wrote my own code to load the script asynchronously following the createElement-insertBefore pattern popularized by the Google Analytics async snippet:
var sNew = document.createElement("script");
sNew.async = true;
sNew.src = "http://ajax.googleapis.com/ajax/libs/jquery/1.5.1/jquery.min.js";
var s0 = document.getElementsByTagName('script')[0];
s0.parentNode.insertBefore(sNew, s0);
Why does using document.write to dynamically insert scripts produce these bad performance effects?
It’s really not surprising if we walk through it step-by-step: We know that loading scripts using normal SCRIPT SRC= markup blocks rendering for all subsequent DOM elements. And we know that document.write is evaluated immediately before script execution releases control and the page resumes being parsed. Therefore, the document.write technique inserts a script using normal SCRIPT SRC= which blocks the rest of the page from rendering.
On the other hand, scripts inserted using the createElement-insertBefore technique do not block rendering. In fact, if document.write generated a createElement-insertBefore snippet then rendering would also not be blocked.
At the bottom of my Loading Script Without Blocking blog post is a decision tree to help developers choose which async technique to use under different scenarios. If you look closely you’ll notice that document.write is never recommended. A lot of things change on the Web, but that advice was true in 2009 and is still true today.