HTTP Archive – new stuff!
Background
The HTTP Archive crawls the world’s top 300K URLs twice each month and records detailed information like the number of HTTP requests, the most popular image formats, and the use of gzip compression. We also crawl the top 5K URLs on real iPhones as part of the HTTP Archive Mobile. In addition to aggregate stats, the HTTP Archive has the same set of data for individual websites plus images and video of the site loading.
I started the project in 2010 and merged it into the Internet Archive in 2011. The data is collected using WebPagetest. The code and data are open source. The hardware, mobile devices, storage, and bandwidth are funded by our generous sponsors:  Google, Mozilla, New Relic, O’Reilly Media, Etsy, Radware, dynaTrace Software, Torbit, Instart Logic, and Catchpoint Systems.
For more information about the HTTP Archive see our About page.
New Stuff!
I’ve made a lot of progress on the HTTP Archive in the last two months and want to share the news in this blog post.
- Github
- A major change was moving the code to Github. It used to be on Google Code but Github is more popular now. There have been several contributors over the years, but I hope the move to Github increases the number of patches contributed to the project.
- Histograms
- The HTTP Archive’s trending charts show the average value of various stats over time. These are great for spotting performance regressions and other changes in the Web. But often it’s important to look beyond the average and see more detail about the distribution. As of today all the relevant trending charts have a corresponding histogram. For an example, take a look at the trending chart for Total Transfer Size & Total Requests and its corresponding histograms. I’d appreciate feedback on these histograms. In some cases I wonder if a CDF would be more appropriate.
- Connections
- We now plot the number of TCP connections that were used to load the website. (All desktop stats are gathered using IE9.) Currently the average is 37 connections per page.
 Â
 - CDNs
- We now record the CDN, if any, for each individual resource. This is currently visible in the CDNs section for individual websites. The determination is based on a reverse lookup of the IP address and a host-to-CDN mapping in WebPagetest.
Custom Metrics
Pat Meenan, the creator of WebPagetest, just added a new feature called custom metrics for gathering additional metrics using JavaScript. The HTTP Archive uses this feature to gather these additional stats:
- Average DOM Depth
- The complexity of the DOM hierarchy affects JavaScript, CSS, and rendering performance. I first saw average DOM depth as a performance metric in DOM Monster. I think it’s a good stat for tracking DOM complexity.
 Â
 - Document Height
- Web pages are growing in many ways such as total size and use of fonts. I’ve noticed pages also getting wider and taller so HTTP Archive now tracks document height and width. You can see the code here. Document width is more constrained by the viewport of the test agent and the results aren’t that interesting, so I only show document height.
 Â
 - localStorage & sessionStorage
- The use of localStorage and sessionStorage can help performance and offline apps, so the HTTP Archive tracks both of these. Right now the 95th percentile is under 200 characters for both, but watch these charts over the next year. I expect we’ll see some growth.
- Iframes
- Iframes are used frequently to contain third party content. This will be another good trend to watch.

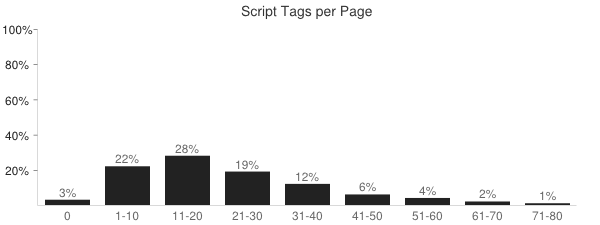
- SCRIPT Tags
- The HTTP Archive has tracked the number of external scripts since its inception, but custom metrics allows us to track the total number of SCRIPT tags (inline and external) in the page.
- Doctype
- Specifying a doctype affects quirks mode and other behavior of the page. Based on the latest crawl, 14% of websites don’t specify a doctype, and “html” is the most popular doctype at 40%. Here are the top five doctypes.
Doctype Percentage html40% html -//W3C//DTD XHTML 1.0 Transitional//EN http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd31% [none] 14% html -//W3C//DTD XHTML 1.0 Strict//EN http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd8% HTML -//W3C//DTD HTML 4.01 Transitional//EN http://www.w3.org/TR/html4/loose.dtd3%
Some of these new metrics are not yet available in the HTTP Archive Mobile but we’re working to add those soon. They’re available as histograms currently, but once we have a few months of data I’ll add trending charts, as well.
What’s next?
Big ticket items on the HTTP Archive TODO list include:
- easier private instance – I estimate there are 20 private instances of HTTP Archive out there today (see here, here, here, here, and here). I applaud these folks because the code and documentation don’t make it easy to setup a private instance. There are thousands of WebPagetest private instances in the world. I feel that anyone running WebPagetest on a regular basis would benefit from storing and viewing the results in HTTP Archive. I’d like to lower the bar to make this happen.
- 1,000,000 URLs – We’ve increased from 1K URLs at the beginning four years ago to 300K URLs today. I’d like to increase that to 1 million URLs on desktop. I also want to increase the coverage on mobile, but that’s going to probably require switching to emulators.
- UI overhaul – The UI needs an update, especially the charts.
In the meantime, I encourage you to take a look at the HTTP Archive. Search for your website to see its performance history. If it’s not there (because it’s not in the top 300K) then add your website to the crawl. And if you have your own questions you’d like answered then try using the HTTP Archive dumps that Ilya Grigorik has exported to Google BigQuery and the examples from bigqueri.es.
Michael | 09-Jun-14 at 3:37 am | Permalink |
Hi Steve,
thanks for your changes, some interesting new graphs to look at! I would be interested in some stats about SPDY or http/2, but I’m not sure if you can already gather them. Usage, number of SPDY connections, SPDY version.
Could be interesting to compare to non-SPDY crawls.
Steve Souders | 09-Jun-14 at 6:50 am | Permalink |
Michael: SPDY/HTTP2 stats would be great to have. Right now we’re using IE9 as our test agent so it won’t get it, but it’s possible we might switch to Chrome in which case we could do it.
Mark Nottingham | 09-Jun-14 at 9:23 am | Permalink |
Hey Steve – way cool!
Am I just missing the histograms? Can’t seem to find them…
Steve Souders | 09-Jun-14 at 9:33 am | Permalink |
Mark: Hi! You can click on any of the histograms in this blog post and it’ll take you to the HTTP Archive website. From the website itself the histograms are in the “Stats” page starting here. There are ~20 histograms on that page. “Stats” are on a per-crawl basis (eg, stats for June 1 2014) so histograms make sense here. On the Trends page are the chronological line plots. Right now they show average, but I’ll probably change those to show median & 95th percentile.
Nicholas Shanks | 11-Jun-14 at 2:46 am | Permalink |
I am seeing some hosts which I thought were CDNs not being shown as such (namely Flickr static file hosts, Google static file hosts, and Yahoo static file hosts):
http://httparchive.org/viewsite.php?u=http%3A%2F%2Fwww.roh.org.uk%2F&l=May%2015%202014
Steve Souders | 11-Jun-14 at 8:37 am | Permalink |
Nicholas: This is based on code in WebPagetest so you can submit a bug there. The likely explanation is the definition of “CDN”.
Saurabh | 28-Aug-14 at 12:30 pm | Permalink |
Hey.. Thanks for this amazing tool, I want to run a my own copy of the HttpArchive crawler with my own mysql instance, I was able to set it up locally. I need to crawl over my own set of URLs, is there a way to configure URLs that it crawls and customize when crawling happens?
I am new to php so tried but could not find such code in the repository. Thanks in advance.
Steve Souders | 29-Aug-14 at 9:42 am | Permalink |
Saurabh: All the code exists to do what you want, but I admit that it has minimal documentation. Let me answer your questions and perhaps that will generate a first draft of code for setting up a private instance of HTTP Archive.
The code for doing the crawl is in the bulktest subdirectory. I use crontab to schedule when the crawl happens. Look at crontab.txt. I schedule crawls for the 1st and 15th of each month. I execute batch_log.php every 30 minutes to move the crawl along.
Wrt the set of URLs, that’s controlled by the commandline options to batch_start.php. I specify no options which means it uses the Alexa Top 1M list of URLs. Instead, you could pass in a file as the first parameter:
batch_start.php urls.txt
where urls.txt contains one URL per line.
The key place for customization is settings.inc where you configure MySQL and the URL to your private instance of WebPagetest. Further WebPagetest config options are specified in bootstrap.inc. You might need to create bulktest/wptkey.inc.php – that’s not in Github as it’s optional depending on your WebPagetest configuration.