I <3 image bytes
Much of my work on web performance has focused on JavaScript and CSS, starting with the early rules Move Scripts to the Bottom and Put Stylesheets at the Top from back in 2007(!). To emphasize these best practices I used to say, “JS and CSS are the most important bytes in the page”.
A few months ago I realized that wasn’t true. Images are the most important bytes in the page.
My focus on JS and CSS was largely motivated by the desire to get the images downloaded as soon as possible. Users see images. They don’t see JS and CSS. It is true that JS and CSS affect what is seen in the page, and even whether and how images are displayed (e.g., JS photo carousels, and CSS background images and media queries). But my realization was JS and CSS are the means by which we get to these images. During page load we want to get the JS and CSS out of the way as quickly as possible so that the images (and text) can be shown.
My main motivation for optimizing JS and CSS is to get rendering to happen as quickly as possible.
Rendering starts very late
With this focus on rendering in mind, I went to the HTTP Archive to see how quickly we’re getting pages to render. The HTTP Archive runs on top of WebPagetest which reports the following time measurements:
- time-to-first-byte (TTFB) – When the first packet of the HTML document arrives.
- start render – When the page starts rendering.
- onload – When window.onload fires.
I extracted the 50th and 90th percentile values for these measurements across the world’s top 300K URLs. As shown, nothing is rendered for the first third of page load time!
| Table 1. Time milestones during page load | |||
| TTFB | start render | onload | |
|---|---|---|---|
| 50th percentile | 610 ms | 2227 ms | 6229 ms |
| 90th percentile | 1780 ms | 5112 ms | 15969 ms |
Preloading
The fact that rendering doesn’t start until the page is 1/3 into the overall page load time is eye-opening. Looking at both the 50th and 90th percentile stats from the HTTP Archive, rendering starts ~32-36% into the page load time. It takes ~10% of the overall page load time to get the first byte. Thus, for ~22-26% of the page load time the browser has bytes to process but nothing is drawn on the screen. During this time the browser is typically downloading and parsing scripts and stylesheets – both of which block rendering on the page.
It used to be that the browser was largely idle during this early loading phase (after TTFB and before start render). That’s because when an older browser started downloading a script, all other downloads were blocked. This is still visible in IE 6&7. Browser vendors realized that while it’s true that constructing the DOM has to wait for a script to download and execute, there’s no reason other resources deeper in the page couldn’t be fetched in parallel. Starting with IE 8 in 2009, browsers started looking past the currently downloading script for other resources (i.e, SCRIPT, IMG, LINK, and IFRAME tags) and preloading those requests in parallel. One study showed preloading makes pages load ~20% faster. Today, all major browsers support preloading. In these Browserscope results I show the earliest version of each major browser where preloading was first supported.
(As an aside, I think preloading is the single biggest performance improvement browsers have ever made. Imagine today, with the abundance of scripts on web pages, what performance would be like if each script was downloaded sequentially and blocked all other downloads.)
Preloading and responsive images
This ties back to this tweet from Jason Grigsby:
I’ll be honest. I’m tired of pushing for resp images and increasingly inclined to encourage devs to use JS to simply break pre-loaders.
The “resp images” Jason refers to are techniques by which image requests are generated by JavaScript. This is generally used to adapt the size of images for different screen sizes. One example is Picturefill. When you combine “pre-loaders” and “resp images” an issue arises – the preloader looks ahead for IMG tags and fetches their SRC, but responsive image techniques typically don’t have a SRC, or have a stub image such as a 1×1 transparent pixel. This defeats the benefits of preloading for images. So there’s a tradeoff:
- Don’t use responsive images so that the preloader can start downloading images sooner, but the images might be larger than needed for the current device and thus take longer to download (and cost more for limited cellular data plans).
- Use responsive images which doesn’t take advantage of preloading which means the images are loaded later after the required JS is downloaded and executed, and the IMG DOM elements have been created.
As Jason says in a follow-up tweet:
The thing that drives me nuts is that almost none of it has been tested. Lots of gospel, not a lot of data.
I don’t have any data comparing the two tradeoffs, but the HTTP Archive data showing that rendering doesn’t start until 1/3 into page load is telling. It’s likely that rendering is being blocked by scripts, which means the IMG DOM elements haven’t been created yet. So at some point after the 1/3 mark the IMG tags are parsed and at some point after that the responsive image JS executes and starts downloading the necessary images.
In my opinion, this is too late in the page load process to initiate the image requests, and will likely cause the web page to render later than it would if the preloader was used to download images. Again, I don’t have data comparing the two techniques. Also, I’m not sure how the preloader works with the responsive image techniques done via markup. (Jason has a blog post that touches on that, The real conflict behind <picture> and @srcset.)
Ideally we’d have a responsive image solution in markup that would work with preloaders. Until then, I’m nervous about recommending to the dev community at large to move toward responsive images at the expense of defeating preloading. I expect browsers will add more benefits to preloading, and I’d like websites to be able to take advantage of those benefits both now and in the future.
Async Scripts – Cached?
I want to re-run the real user cache experiment that Tenni Theurer and I ran back in 2007. I’m designing the experiment now and will share that design in this blog when it’s well-baked. One change is I’d like to use an external script as the cached response that is tested. Another change is I want the experiment to be a snippet that any website can embed. That allows me to crowdsource results from websites with a wider range of session behaviors, user profiles, browsers, etc.
Since I’ll be asking websites to embed this 3rd party script, it’s important that it not harm performance and avoid frontend SPOF. I’ll do this using JavaScript to dynamically request the external script using the typical createElement-insertBefore pattern:
var newscript = document.createElement("script");
newscript.async = true;
newscript.src = document.location.protocol + "//NOTstevesouders.com/testscript.js";
var s0 = document.getElementsByTagName('script')[0];
s0.parentNode.insertBefore(newscript, s0);
But I wondered: Does loading an external script this way affect caching behavior?
I’ve been using this pattern for years and know that caching headers for dynamically-loaded scripts are respected in all the major desktop & mobile browsers, but what about other browsers? To answer this question I created a Browserscope user test last week. The Caching Async Scripts test page loads a script dynamically. The script has a far future expiration date so on the next page it should be read from cache. This is tested by measuring the script’s load time – normally it takes 6 seconds to load so if it’s far less than that it must have been read from cache.
I tweeted the test’s URL asking people to run the test. Thanks to everyone who ran it! The crowdsourced Browserscope results show data for over sixty browsers including Blackberry, Epiphany, and PlayStation. Happily, and surprisingly, it shows that every browser honors caching headers for scripts loaded dynamically. That’s great news in general, and with regard to re-running the cache experiment means that I can feel comfortable using this pattern to load the cached script while avoiding frontend SPOF.
Self-updating scripts
- The previous code had a race condition when
beacon.jscalleddocument.body.appendChildbefore BODY existed. This was fixed. - Some users reported the
update.phpiframe was opened in a new tab in IE8. I can’t repro this bug but am investigating.
Analyzing your site using Page Speed or YSlow often produces lower scores than you might expect due to 3rd party resources with short cache times. 3rd party snippet owners use short cache times so that users receive updates in a timely fashion, even if this means slowing down the site owner’s page.
Stoyan and I were discussing this and wondered if there was a way to have longer cache times and update resources when necessary. We came up with a solution. It’s simple and reliable. Adopting this pattern will reduce unnecessary HTTP requests resulting in faster pages and happier users, as well as better Page Speed and YSlow scores.
Long cache & revving URLs
Caching is an important best practice for making websites load faster. (If you’re already familiar with caching and 304s you may want to skip to the self-updating section.) Caching is easily achieved by giving resources an expiration date far in the future using the Cache-Control response header. For example, this tells the browser that the response can be cached for 1 year:
Cache-Control: max-age=31536000
But what happens if you make changes to the resource before the year is over? Users who have the old version in their cache won’t get the new version until the resource expires, meaning it would take 1 year to update all users. The simple answer is for the developer to change the resource’s URL. Often this is done by adding a “fingerprint” to the path, such as the source control version number, file timestamp, or checksum. Here’s an example for a script from Facebook:
http://static.ak.fbcdn.net/rsrc.php/v1/yx/r/N-kcJF3mlg6.js
It’s likely that if you compare the resource URLs for major websites over time you’ll see these fingerprints changing with each release. Using the HTTP Archive we see how the URL changes for Facebook’s main script:
http://static.ak.fbcdn.net/rsrc.php/v1/y2/r/UVaDehc7DST.js(March 1)http://static.ak.fbcdn.net/rsrc.php/v1/y-/r/Oet3o2R_9MQ.js(March 15)http://static.ak.fbcdn.net/rsrc.php/v1/yS/r/B-e2tX_mUXZ.js(April 1)http://static.ak.fbcdn.net/rsrc.php/v1/yx/r/N-kcJF3mlg6.js(April 15)
Facebook sets a 1 year cache time for this script, so when they make changes they rev the URL to make sure all users get the new version immediately. Setting long cache times and revving the URL is a common solution for websites focused on performance. Unfortunately, this isn’t possible when it comes to 3rd party snippets.
Snippets don’t rev
Revving a resource’s URL is an easy solution for getting updates to the user when it comes to the website’s own resources. The website owner knows when there’s an update and since they own the web page they can change the resource URL.
3rd party snippets are a different story. In most cases, 3rd party snippets contain the URL for a bootstrap script. For example, here’s the Tweet Button snippet:
<a href="https://twitter.com/share" class="twitter-share-button"
data-lang="en">Tweet</a>
<script>
!function(d,s,id){
var js,fjs=d.getElementsByTagName(s)[0];
if(!d.getElementById(id)){
js=d.createElement(s); js.id=id;
js.src="//platform.twitter.com/widgets.js";
fjs.parentNode.insertBefore(js,fjs);
}}(document,"script","twitter-wjs");
</script>
Website owners paste this snippet code into their pages. In the event of an emergency update, the Twitter team can’t rev the widgets.js URL because they don’t have access to change all the web pages containing this snippet. Notifying all the website owners to update the snippet isn’t an option, either. Since there’s no way to rev the URL, bootstrap scripts typically have a short cache time to ensure users get updates quickly. Twitter’s widgets.js is cacheable for 30 minutes, Facebook’s all.js is cacheable for 15 minutes, and Google Analytics’ ga.js is cacheable for 2 hours. This is much shorter than the recommended practice of setting the expiration date a month or more in the future.
Conditional GETs hurt performance
Unfortunately, these short cache times for bootstrap scripts have a negative impact on web performance. When the snippet’s resource is requested after the cache time has expired, instead of reading the resource from cache the browser has to issue a Conditional GET request (containing the If-Modified-Since and If-None-Match request headers). Even if the response is a simple 304 Not Modified with no response body, the time it takes to complete that roundtrip impacts the user experience. That impact varies depending on whether the bootstrap script is loaded in the normal way vs. asynchronously.
Loading scripts the “normal way” means using HTML: <script src="..."></script>. Scripts loaded this way have several negative impacts: they block all subsequent DOM elements from rendering, and in older browsers they block subsequent resources from being downloaded. These negative impacts also happen when the browser makes a Conditional GET request for a bootstrap script with a short cache time.
If the snippet is an async script, as is the case for widgets.js, the negative impact is reduced. In this case the main drawback impacts the widget itself – it isn’t rendered until the response to the Conditional GET is received. This is disconcerting to users because they see these async widgets popping up in the page after the surrounding content has already rendered.
Increasing the bootstrap script’s cache time reduces the number of Conditional GET requests which in turn avoids these negative impacts on the user experience. But how can we increase the cache time and still get updates to the user in a timely fashion without the ability to rev the URL?
Self-updating bootstrap scripts
A bootstrap script is defined as a 3rd party script with a hardwired URL that can’t be changed. We want to give these scripts long cache times so they don’t slow down the page, but we also want the cached version to get updated when there’s a change. There are two main problems to solve: notifying the browser when there’s an update, and replacing the cached bootstrap script with the new version.
update notification: Here we make the assumption that the snippet is making some subsequent request to the 3rd party server for dynamic data, to send a beacon, etc. We piggyback on this. In the case of the Tweet Button, there are four requests to the server: one for an iframe HTML document, one for JSON containing the tweet count, and two 1×1 image beacons (presumably for logging). Any one of these could be used to trigger an update. The key is that the bootstrap script must contain a version number. That version number is then passed back to the snippet server in order for it to detect if an update is warranted.
replacing the cached bootstrap script: This is the trickier part. If we give the bootstrap script a longer cache time (which is the whole point of this exercise), we have to somehow overwrite that cached resource even though it’s not yet expired. We could dynamically re-request the bootstrap script URL, but it’ll just be read from cache. We could rev the URL by adding a querystring, but that won’t overwrite the cached version with the hardwired URL referenced in the snippet. We could do an XHR and modify the caching headers using setRequestHeader, but that doesn’t work across all browsers.
Stoyan struck on the idea of dynamically creating an iframe that contains the bootstrap script, and then reloading that iframe. When the iframe is reloaded it’ll generate a Conditional GET request for the bootstrap script (even though the bootstrap script is cached and still fresh), and the server will respond with the updated bootstrap script which overwrites the old one in the browser’s cache. We’ve achieved both goals: a longer cache time while preserving the ability to receive updates when needed. And we’ve replaced numerous Conditional GET requests (every 30 minutes in the case of widgets.js) with only one Conditional GET request when the bootstrap script is actually modified.
An example
Take a look at this Self-updating Scripts example modeled after Google Analytics. This example contains four pages.
page 1: The first page loads the example snippet containing bootstrap.js:
(function() {
var s1 = document.createElement('script');
s1.async = true;
s1.src = 'http://souders.org/tests/selfupdating/bootstrap.js';
var s0 = document.getElementsByTagName('script')[0];
s0.parentNode.insertBefore(s1, s0);
})();
Note that the example is hosted on stevesouders.com but the snippet is served from souders.org. This shows that the technique works for 3rd party snippets served from a different domain. At this point your browser cache contains a copy of bootstrap.js which is cacheable for 1 week and contains a “version number” (really just a timestamp). The version (timestamp) of bootstrap.js is shown in the page, for example, 16:23:53. A side effect of bootstrap.js is that it sends a beacon (beacon.js) back to the snippet server. For now the beacon returns an empty response (204 No Content).
page 2: The second page just loads the snippet again to confirm we’re using the cache. This time bootstrap.js is read from cache, so the timestamp should be the same, e.g., 16:23:53. A beacon is sent but again the response is empty.
page 3: Here’s where the magic happens. Once again bootstrap.js is read from cache (so you should see the same version timestamp again). But this time when it sends the beacon the server returns a notification that there’s an update. This is done by returning some JavaScript inside beacon.js:
(function() {
var doUpdate = function() {
if ( "undefined" === typeof(document.body) || !document.body ) {
setTimeout(doUpdate, 500);
}
else {
var iframe1 = document.createElement("iframe");
iframe1.style.display = "none";
iframe1.src = "http://souders.org/tests/selfupdating/update.php?v=[ver #]";
document.body.appendChild(iframe1);
}
};
doUpdate();
})();
The iframe src points to update.php:
<html>
<head>
<script src="http://souders.org/tests/selfupdating/bootstrap.js"></script>
</head>
<body>
<script>
if (location.hash === '') {
location.hash = "check";
location.reload(true);
}
</script>
</body>
</html>
The two key pieces of update.php are a reference to bootstrap.js and the code to reload the iframe. The location hash property is assigned a string to avoid reloading infinitely. The best way to understand the sequence is to look at the waterfall chart.

This page (newver.php) reads bootstrap.js from cache (1). The beacon.js response contains JavaScript that loads update.php in an iframe and reads bootstrap.js from cache (2). But when update.php is reloaded it issues a request for bootstrap.js (3) which returns the updated version and overwrites the old version in the browser’s cache. Voilà !
page 4: The last page loads the snippet once again, but this time it reads the updated version from the cache, as indicated by the newer version timestamp , e.g., 16:24:17.
Observations & adoption
One observation about this approach is the updated version is used the next time the user visits a page that needs the resource (similar to the way app cache works). We saw this in page 3 where the old version of bootstrap.js was used in the snippet and the new version was downloaded afterward. With the current typical behavior of short cache times and many Conditional GET requests the new version is used immediately. However, it’s also true with the old approach that if an update occurs while a user is in the middle of a workflow, the user won’t get the new version for 30 minutes or 2 hours (or whatever the short cache time is). Whereas with the new approach the user would get the update as soon as it’s available.
It would be useful to do a study about whether this approach increases or decreases the number of beacons with an outdated bootstrap script. Another option is to always check for an update. This would be done by having the bootstrap script append and reload the update.php iframe when it’s done. The downside is this would greatly increase the number of Conditional GET requests. The plus side is the 3rd party snippet owner doesn’t have to deal with the version number logic.
An exciting opportunity with this new approach is to treat update.php as a manifest list. It can reference bootstrap.js as well as any other resources that have long cache times but need to be overwritten in the browser’s cache. It should be noted that update.php doesn’t need to be a dynamic page – it can be a static page with a far future expiration date. Also, the list of resources can be altered to reflect only the resources that need to be updated (based on the version number received).
A nice aspect of this approach is that existing snippets don’t need to change. All of the changes necessary to adopt this self-updating behavior are on the snippet owner’s side:
- Add a version number to the bootstrap script.
- Pass back the version number to the snippet server via some other request that can return JavaScript. (Beacons work – they don’t have to be 1×1 transparent images.)
- Modify that request handler to return JavaScript that creates a dynamic iframe when the version is out-of-date.
- Add an
update.phppage that includes the bootstrap script (and other resources you want to bust out of cache). - Increase the cache time for the bootstrap script! 10 years would be great, but going from 30 minutes to 1 week is also a huge improvement.
If you own a snippet I encourage you to consider this self-updating approach for your bootstrap scripts. It’ll produce faster snippets, a better experience for your users, and fewer requests to your server.
Don’t docwrite scripts
In yesterday’s blog post, Making the HTTP Archive faster, one of the biggest speedups came from not using a script loader. It turns out that script loader was using document.write to load scripts dynamically. I wrote about the document.write technique in Loading Script Without Blocking back in April 2009, as well as in Even Faster Web Sites (chapter 4). It looks something like this:
document.write('<script src="' + src + '" type="text/javascript"><\/script>'):
The problem with document.write for script loading is:
- Every DOM element below the inserted script is blocked from rendering until the script is done downloading (example).
- It blocks other dynamic scripts (example). One exception is if multiple scripts are inserted usingÂ
document.writewithin the same SCRIPT block (example).
Because the script loader was using document.write, the page I was optimizing rendered late and other async scripts in the page took longer to download. I removed the script loader and instead wrote my own code to load the script asynchronously following the createElement-insertBefore pattern popularized by the Google Analytics async snippet:
var sNew = document.createElement("script");
sNew.async = true;
sNew.src = "http://ajax.googleapis.com/ajax/libs/jquery/1.5.1/jquery.min.js";
var s0 = document.getElementsByTagName('script')[0];
s0.parentNode.insertBefore(sNew, s0);
Why does using document.write to dynamically insert scripts produce these bad performance effects?
It’s really not surprising if we walk through it step-by-step: We know that loading scripts using normal SCRIPT SRC= markup blocks rendering for all subsequent DOM elements. And we know that document.write is evaluated immediately before script execution releases control and the page resumes being parsed. Therefore, the document.write technique inserts a script using normal SCRIPT SRC= which blocks the rest of the page from rendering.
On the other hand, scripts inserted using the createElement-insertBefore technique do not block rendering. In fact, if document.write generated a createElement-insertBefore snippet then rendering would also not be blocked.
At the bottom of my Loading Script Without Blocking blog post is a decision tree to help developers choose which async technique to use under different scenarios. If you look closely you’ll notice that document.write is never recommended. A lot of things change on the Web, but that advice was true in 2009 and is still true today.
Making the HTTP Archive faster
This week I finally got time to do some coding on the HTTP Archive. Coincidentally (ironically?) I needed to focus on performance. Hah! This turned out to be a good story with a few takeaways – info about the HTTP Archive, some MySQL optimizations, and a lesson learned about dynamic script loaders.
Setting the stage
The HTTP Archive started in November 2010 by analyzing 10K URLs and storing their information (subresource URLs, HTTP headers, sizes, etc.) in a MySQL database. We do these runs twice each month. In November 2011 we began increasing the number of URLs to 25K, 50K, 75K, and finally hit 100K this month. Our goal is to hit 1M URLs by the end of 2012.

The MySQL schema in use today is by-and-large the same one I wrote in a few hours back in November 2010. I didn’t spend much time on it – I’ve created numerous databases like this and was able to quickly get something that got the job done and was fast. I knew it wouldn’t scale as the size of the archive and number of URLs grew, but I left that for another day.
That day had arrived.
DB schema
The website was feeling slow. I figured I had reached that curve in the hockey stick where my year-old schema that worked on two orders of magnitude less data was showing its warts. I saw plenty of slow queries in the log. I occasionally did some profiling and was easily able to identify queries that took 500 ms or more; some even took 10+ seconds. I’ve built big databases before and had some tricks up my sleeve so I sat down today to pinpoint the long poles in the tent and cut them down.
The first was pretty simple. The urls table has over 1M URLs. The only index was based on the URL string – a blob. It took 500-1000 ms to do a lookup. The main place this happens is looking up the URL’s rank, for example, in the last crawl Whole Foods was ranked 5,872 (according to Alexa). This is a fairly non-critical piece of information, so slowing down the page 500-1000 ms wasn’t acceptable. Plus this seems like a simple lookup ripe for optimizing.
When I described this problem to my Velocity co-chair, John Allspaw, he suggested creating a hash for the URL that would be faster to index. I understood the concept but had never done this before. I didn’t find any obvious pointers out there on “the Web” so I rolled my own. I started with md5(), but that produced a fairly long string that was alphanumeric (hex):
select md5("http://www.wholefoodsmarket.com/");
=> 0a0936fe5c690a3b468a6895efaaff83
I didn’t think it would be that much faster to index off the md5() hex string (although I didn’t test this). Assuming that md5() strings are evenly distributed, I settled on taking a substring:
select substring(md5("http://www.wholefoodsmarket.com/"), 1, 4);
=> 0a09
This was still hex and I thought an int would be a faster index (but again, I didn’t test this). So I added a call to conv() to convert the hex to an int:
select conv(substring(md5("http://www.wholefoodsmarket.com/"), 1, 4), 16, 10);
=> 2569
I was pretty happy. This maps URLs across 64K hashes. I’m assuming they’re evenly distributed. This conversion is only done a few times per page so the overhead is low. If you have a better solution please comment below, but overall I thought this would work – and it did! Those 500+ ms queries went down to < 1 ms. Yay!
But the page was still slow. Darn!
Duh – it’s the frontend
This and a few other MySQL changes shaved a good 2-3 seconds of the page load time but the page still felt slow. The biggest problem was rendering – I could tell the page arrived quickly but something was blocking the rendering. This is more familiar performance territory for me so I gleefully rolled up my sleeves and pulled out my WPO toolbox.
The page being optimized is viewsite.php. I used WebPagetest to capture a waterfall chart and screenshots for Chrome 18, Firefox 11, IE 8, and IE 9. The blocking behavior and rendering times were not what I consider high performance. (Click on the waterfall chart to go to the detailed WebPagetest results.)
Chrome 18:

Firefox 11:

Internet Explorer 8:

Internet Explorer 9:

These waterfall charts looked really wrong to me. The start render times (green vertical line) were all too high: Chrome 1.2 seconds, Firefox 2.6 seconds, IE8 1.6 seconds, and IE9 2.4 seconds. Also, too many resources were downloading and potentially blocking start render. This page has a lot of content, but most of the scripts are loaded asynchronously and so shouldn’t block rendering. Something was defeating that optimization.
Docwrite blocks
I immediately honed in on jquery.min.js because it was often in the critical path or appeared to push out the start render time. I saw in the code that it was being loaded using Google Libraries API. Here’s the code that was being used to load jquery.min.js:
<script src="http://www.google.com/jsapi"></script>
<script>
google.load("jquery", "1.5.1");
</script>
I’ve looked at (and built) numerous async script loaders and know there are a lot of details to get right, so I dug into the jsapi script to see what was happening. I saw the typical createElement-insertBefore pattern popularized by the Google Analytics async snippet. But upon walking through the code I discovered that jquery.min.js was being loaded by this line:
m.write('<script src="'+b+'" type="text/javascript"><\/script>'):
The jsapi script was using document.write to load jquery.min.js. While it’s true that document.write has some asynchronous benefits, it’s more limited than the createElement-insertBefore pattern. Serendipitously, I was just talking with someone a few weeks ago about deprecating the jsapi script because it introduces an extra HTTP request, and instead recommend that people just load the script directly. So that’s what I did.
We don’t need no stinkin’ script loader
In my case I knew that jquery.min.js could be loaded async, so I replaced the google.load code with this:
var sNew = document.createElement("script");
sNew.async = true;
sNew.src = "http://ajax.googleapis.com/ajax/libs/jquery/1.5.1/jquery.min.js";
var s0 = document.getElementsByTagName('script')[0];
s0.parentNode.insertBefore(sNew, s0);
This made the start render times and waterfall charts look much better:
Chrome 18:

Firefox 11:

Internet Explorer 8:

Internet Explorer 9:

There was better parallelization of downloads and the start render times improved. Chrome went from 1.2 to 0.9 seconds. Firefox went from 2.6 to 1.3 seconds. IE8 went from 1.6 to 1.1 seconds. IE9 went from 2.4 to 1.0 seconds.
This was a fun day spent making the HTTP Archive faster. Even though I consider myself a seasoned veteran when it comes to web performance, I still found a handful of takeaways including some oldies that still ring true:
- Even for web pages that have significant backend delays, don’t forget to focus on the frontend. After all, that is the Performance Golden Rule.
- Be careful using script loaders. They have to handle diverse script loading scenarios across a large number of browsers. If you know what you want it might be better to just do it yourself.
- Be careful using JavaScript libraries. In this case
jquery.min.jsis only being used for the drop down About menu. That’s 84K (~30K compressed) of JavaScript for a fairly simple behavior.
If you’re curious about why document.write results in worse performance for dynamic script loading, I’ll dig into that in tomorrow’s blog post. Hasta mañana.
Frontend SPOF in Beijing
This past December I contributed an article called Frontend SPOF in Beijing to PerfPlanet’s Performance Calendar. I hope that everyone who reads my blog also read the Performance Calendar – it’s an amazing collection of web performance articles and gurus. But in case you don’t I’m cross-posting it here. I saw a great presentation from Pat Meenan about frontend SPOF and want to raise awareness around this issue. This post contains some good insights.
Make sure to read PerfPlanet – it’s a great aggregator of WPO blog posts.
Now – flash back to December 2011…
I’m at Velocity China in Beijing as I write this article for the Performance Calendar. Since this is my second time to Beijing I was better prepared for the challenges of being behind the Great Firewall. I knew I couldn’t access popular US websites like Google, Facebook, and Twitter, but as I did my typical surfing I was surprised at how many other websites seemed to be blocked.
Business Insider
It didn’t take me long to realize the problem was frontend SPOF – when a frontend resource (script, stylesheet, or font file) causes a page to be unusable. Some pages were completely blank, such as Business Insider:
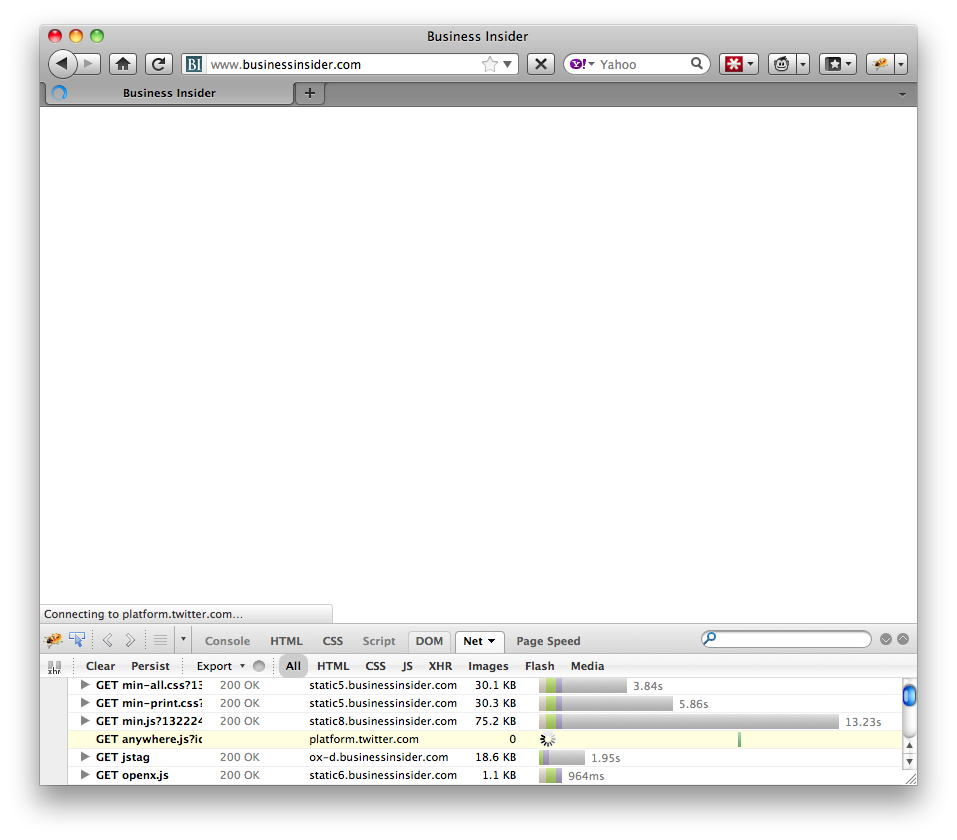
Firebug’s Net Panel shows that anywhere.js is taking a long time to download because it’s coming from platform.twitter.com – which is blocked by the firewall. Knowing that scripts block rendering of all subsequent DOM elements, we form the hypothesis that anywhere.js is being loaded in blocking mode in the HEAD. Looking at the HTML source we see that’s exactly what is happening:
<head> ... <!-- Twitter Anywhere --> <script src="https://platform.twitter.com/anywhere.js?id=ZV0...&v=1" type="text/javascript"></script> <!-- / Twitter Anywhere --> ... </head> ... <body>
If anywhere.js had been loaded asynchronously this wouldn’t happen. Instead, since anywhere.js is loaded the old way with <SCRIPT SRC=..., it blocks all the DOM elements that follow which in this case is the entire BODY of the page. If we wait long enough the request for anywhere.js times out and the page begins to render. How long does it take for the request to timeout? Looking at the “after†screenshot of Business Insider we see it takes 1 minute and 15 seconds for the request to timeout. That’s 1 minute and 15 seconds that the user is left staring at a blank white screen waiting for the Twitter script!

CNET
CNET has a slightly different experience; the navigation header is displayed but the rest of the page is blocked from rendering:

eyewonder.com.Looking in Firebug we see that wrapper.js from cdn.eyewonder.com is “pending†– this must be another domain that’s blocked by the firewall. Based on where the rendering stops our guess is that the wrapper.js SCRIPT tag is immediately after the navigation header and is loaded in blocking mode thus preventing the rest of the page from rendering. The HTML confirms that this is indeed what’s happening:
<header> ... </header> <script src="http://cdn.eyewonder.com/100125/771933/1592365/wrapper.js"></script> <div id="rb_wrap"> <div id="rb_content"> <div id="contentMain">
O’Reilly Radar
Everyday I visit O’Reilly Radar to read Nat Torkington’s Four Short Links. Normally Nat’s is one of many stories on the Radar front page, but going there from Beijing shows a page with only one story:
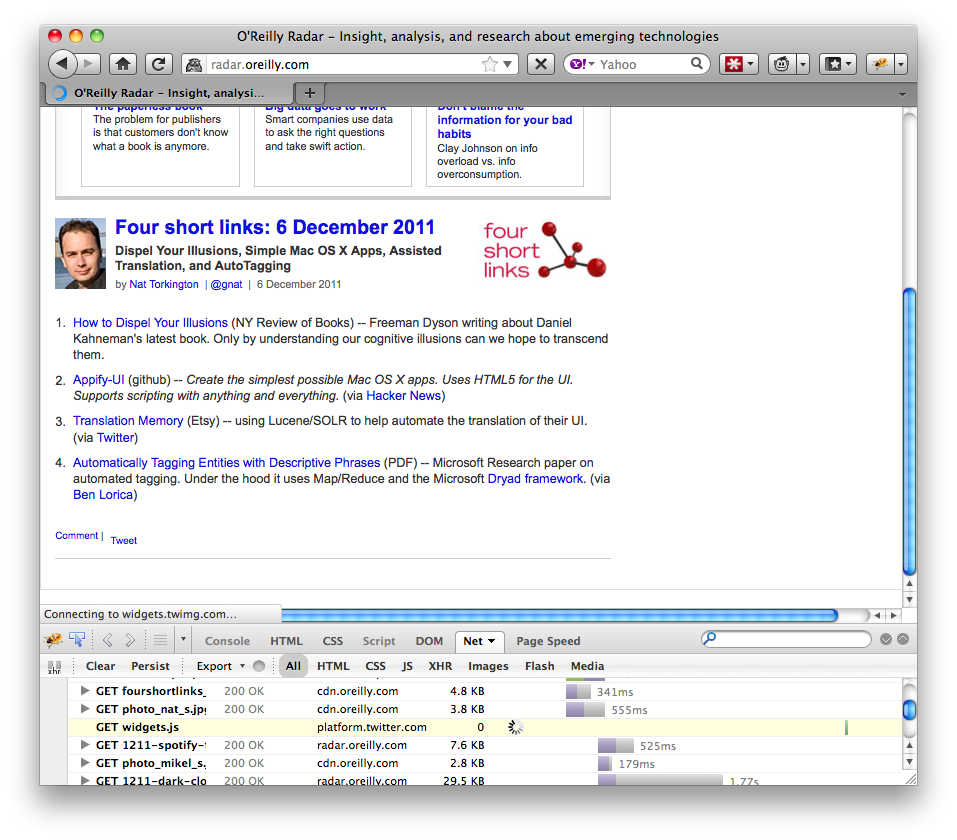
At the bottom of this first story there’s supposed to be a Tweet button. This button is added by the widgets.js script fetched from platform.twitter.com which is blocked by the Great Firewall. This wouldn’t be an issue if widgets.js was fetched asynchronously, but sadly a peek at the HTML shows that’s not the case:
<a href="...">Comment</a> | <span class="social-counters"> <span class="retweet"> <a href="http://twitter.com/share" class="twitter-share-button" data-count="horizontal" data-url="http://radar.oreilly.com/2011/12/four-short-links-6-december-20-1.html" data-text="Four short links: 6 December 2011" data-via="radar" data-related="oreillymedia:oreilly.com">Tweet</a> <script src="http://platform.twitter.com/widgets.js" type="text/javascript"></script> </span>
The cause of frontend SPOF
One possible takeaway from these examples might be that frontend SPOF is specific to Twitter and eyewonder and a few other 3rd party widgets. Sadly, frontend SPOF can be caused by any 3rd party widget, and even from the main website’s own scripts, stylesheets, or font files.
Another possible takeaway from these examples might be to avoid 3rd party widgets that are blocked by the Great Firewall. But the Great Firewall isn’t the only cause of frontend SPOF – it just makes it easier to reproduce. Any script, stylesheet, or font file that takes a long time to return has the potential to cause frontend SPOF. This typically happens when there’s an outage or some other type of failure, such as an overloaded server where the HTTP request languishes in the server’s queue for so long the browser times out.
The true cause of frontend SPOF is loading a script, stylesheet, or font file in a blocking manner. The table in my frontend SPOF blog post shows when this happens. It’s really the website owner who controls whether or not their site is vulnerable to frontend SPOF. So what’s a website owner to do?
Avoiding frontend SPOF
The best way to avoid frontend SPOF is to load scripts asynchronously. Many popular 3rd party widgets do this by default, such as Google Analytics, Facebook, and Meebo. Twitter also has an async snippet for the Tweet button that O’Reilly Radar should use. If the widgets you use don’t offer an async version you can try Stoyan’s Social button BFFs async pattern.
Another solution is to wrap your widgets in an iframe. This isn’t always possible, but in two of the examples above the widget is eventually served in an iframe. Putting them in an iframe from the start would have avoided the frontend SPOF problems.
For the sake of brevity I’ve focused on solutions for scripts. Solutions for font files can be found in my @font-face and performance blog post. I’m not aware of much research on loading stylesheets asynchronously. Causing too many reflows and FOUC are concerns that need to be addressed.
Call to action
Business Insider, CNET, and O’Reilly Radar all have visitors from China, and yet the way their pages are constructed delivers a bad user experience where most if not all of the page is blocked for more than a minute. This isn’t a P2 frontend JavaScript issue. This is an outage. If the backend servers for these websites took 1 minute to send back a response, you can bet the DevOps teams at Business Insider, CNET, and O’Reilly wouldn’t sleep until the problem was fixed. So why is there so little concern about frontend SPOF?
Frontend SPOF doesn’t get much attention – it definitely doesn’t get the attention it deserves given how easily it can bring down a website. One reason is it’s hard to diagnose. There are a lot of monitors that will start going off if a server response time exceeds 60 seconds. And since all that activity is on the backend it’s easier to isolate the cause. Is it that pagers don’t go off when clientside page load times exceed 60 seconds? That’s hard to believe, but perhaps that’s the case.
Perhaps it’s the way page load times are tracked. If you’re looking at worldwide medians, or even averages, and China isn’t a major audience your page load time stats might not exceed alert levels when frontend SPOF happens. Or maybe page load times are mostly tracked using synthetic testing, and those user agents aren’t subjected to real world issues like the Great Firewall.
One thing website owners can do is ignore frontend SPOF until it’s triggered by some future outage. A quick calculation shows this is a scary choice. If a 3rd party widget has a 99.99% uptime and a website has five widgets that aren’t async, the probability of frontend SPOF is 0.05%. If we drop uptime to 99.9% the probability of frontend SPOF climbs to 0.5%. Five widgets might be high, but remember that “third party widget†includes ads and metrics. Also, the website’s own resources can cause frontend SPOF which brings the number even higher. The average website today contains 14 scripts any of which could cause frontend SPOF if they’re not loaded async.
Frontend SPOF is a real problem that needs more attention. Website owners should use async snippets and patterns, monitor real user page load times, and look beyond averages to 95th percentiles and standard deviations. Doing these things will mitigate the risk of subjecting users to the dreaded blank white page. A chain is only as strong as its weakest link. What’s your website’s weakest link? There’s a lot of focus on backend resiliency. I’ll wager your weakest link is on the frontend.
[Originally posted as part of PerfPlanet’s Performance Calendar 2011.]
JavaScript Performance
Last night I spoke at the San Francisco JavaScript Meetup. I gave a brand new talk called JavaScript Performance that focuses on script loading and async snippets. The snippet example I chose was the Google Analytics async snippet. The script-loading part of that snippet is only six lines, but a lot of thought and testing went into it. It’s a great prototype to use if you’re creating your own async snippet. I’ll tweet if/when the video of my talk comes out, but in the meantime the slides (Slideshare, pptx) do a good job of relaying the information.
There are two new data points from the presentation that I want to call out in this blog post.
Impact of JavaScript
The presentation starts by suggesting that JavaScript is typically the #1 place to look for making a website faster. My anecdotal experience supports this hypothesis, but I wanted to try to do some quantitative verification. As often happens, I turned to WebPagetest.
I wanted to test the Alexa Top 100 URLs with and without JavaScript. To load these sites withOUT JavaScript I used WebPagetest’s “block” feature. I entered “.js” which tells WebPagetest to ignore every HTTP request with a URL that contains that string. Each website was loaded three times and the median page load time was recorded. I then found the median of all these median page load times.
The median page load with JavaScript is 3.65 seconds. Without JavaScript the page load time drops to 2.487 seconds – a 31% decrease. (Here’s the data in WebPagetest: with JavaScript, without JavaScript.) It’s not a perfect analysis: Some script URLs don’t contain “.js” and inline script blocks are still executed. I think this is a good approximation and I hope to do further experiments to corroborate this finding.

Async Execution Order & Onload
The other new infobyte has to do with the async=true line from the GA async snippet. The purpose of this line is to cause the ga.js script to not block other async scripts from being executed. It turns out that some browsers preserve the execution order of scripts loaded using the insertBefore technique, which is the technique used in the GA snippet:
ga.type = ‘text/javascript’;
ga.async = true;
ga.src = (‘https:’ == document.location.protocol ? ‘https://ssl’ : ‘http://www’) + ‘.google-analytics.com/ga.js’;
var s = document.getElementsByTagName(‘script’)[0];
s.parentNode.insertBefore(ga, s);
Preserving execution order of async scripts makes the page slower. If the first async script takes a long time to download, all the other async scripts are blocked from executing, even if they download sooner. Executing async scripts immediately as they’re downloaded results in a faster page load time. I knew old versions of Firefox had this issue, and setting async=true fixed the problem. But I wanted to see if any other browsers also preserved execution order of async scripts loaded this way, and whether setting async=true worked.
To answer these questions I created a Browserscope user test called Async Script Execution Order. I tweeted the test URL and got 348 results from 60+ different browsers. (Thanks to all the people that ran the test! I still need results from more mobile browsers so please run the test if you have a browser that’s not covered.) Here’s a snapshot of the results:

The second column shows the results of loading two async scripts with the insertBefore pattern AND setting async=true. The third column shows the results if async is NOT set to true. Green means the scripts execute immediately (good) and red indicates that execution order is preserved (bad).
The results show that Firefox 3.6, OmniWeb 622, and all versions of Opera preserve execution order. Setting async=true successfully makes the async scripts execute immediately in Firefox 3.6 and OmniWeb 622, but not in Opera. Although this fix only applies to a few browsers, its small cost makes it worthwhile. Also, if we get results for more mobile browsers I would expect to find a few more places where the fix is necessary.
I also tested whether these insertBefore-style async scripts block the onload event. The results, shown in the fourth column, are mixed if we include older browsers, but we see that newer browsers generally block the onload event when loading these async scripts – this is true in Android, Chrome, Firefox, iOS, Opera, Safari, and IE 10. This is useful to know if you wonder why you’re still seeing long page load times even after adopting async script loading. It also means that code in your onload handler can’t reliably assume async scripts are loaded because of the many browsers out there that do not block the onload event, including IE 6-9.
And a final shout out to the awesomeness of the Open Source community that makes tools like WebPagetest and Browserscope available – thanks Pat and Lindsey!
frontend SPOF survey
Pat Meenan had a great blog post yesterday, Testing for Frontend SPOF. “SPOF” means single point of failure. I coined the term frontend SPOF to describe the all-too-likely situation where the HTML document returns successfully, but some other resource (a stylesheet, script, or font file) blocks the entire website from loading. This typically manifests itself as a blank white screen that the user stares out for 20 seconds or longer.
Frontend SPOF happens most frequently with third party content. If the HTML document returns successfully, then all the resources from the main website are likely to return successfully, as well. Third party content, however, isn’t controlled by the main website and thus could be suffering an outage or overload while the main website is working fine. As a result, the uptime of a website is no greater than the availability of the third party resources it uses that are in a position to cause frontend SPOF.
In my blog post of the same name I describe how Frontend SPOF happens and ways to avoid it, but I don’t provide a way for website owners to determine which third party resources may cause frontend SPOF. This is where Pat comes in. He’s created a public blackhole server: blackhole.webpagetest.org with the static IP address 72.66.115.13. Pointing your third party resources to this blackhole and reloading the page tells you if those resources cause frontend SPOF. Since Pat is the creator of WebPagetest.org, he has integrated this into the scripting capabilities of that tool so website owners can load their website and determine if any third party resources cause frontend SPOF.
/etc/hosts
I took a different approach outlined by Pat: I added the following lines to my /etc/hosts file (your location may vary) mapping these third party hostnames to point to the blackhole server:
72.66.115.13 apis.google.com 72.66.115.13 www.google-analytics.com 72.66.115.13 connect.facebook.net 72.66.115.13 platform.twitter.com 72.66.115.13 s7.addthis.com 72.66.115.13 l.addthiscdn.com 72.66.115.13 cf.addthis.com 72.66.115.13 api-public.addthis.com 72.66.115.13 widget.quantcast.com 72.66.115.13 ak.quantcast.com 72.66.115.13 assets.omniture.com 72.66.115.13 www.omniture.com 72.66.115.13 scripts.omniture.com 72.66.115.13 b.voicefive.com 72.66.115.13 ar.voicefive.com 72.66.115.13 c.statcounter.com 72.66.115.13 www.statcounter.com 72.66.115.13 www-beta.statcounter.com 72.66.115.13 js.revsci.net
After restarting my browser all requests to these hostnames will timeout. Pat’s blog post mentions 20 seconds for a timeout. He was running on Windows. I’m running on my Macbook where the timeout is 75 seconds! Any website that references third party content on these hostnames in a way that produces frontend SPOF will be blank for 75 seconds – an easy failure to spot.
survey says
THE GOOD: At this point I started loading the top 100 US websites. I was pleasantly surprised. None of the top 20 websites suffered from frontend SPOF. There were several that loaded third party content from these hostnames, but they had safeguarded themselves:
- MSN makes a request to
ar.voicefive.com, but does it asynchronously using a document.write technique. - AOL references
platform.twitter.com, but puts the SCRIPT tag at the very bottom of the BODY so page rendering isn’t blocked. - IMDB uses the async version of Google Analytics, and puts the
platform.twitter.comwidget in an iframe. - LiveJournal goes above and beyond by wrapping the Google +1 and Facebook widgets in a homegrown async script loader.
THE BAD: Going through the top 100 I found five websites that had frontend SPOF:
- CNET loads
http://platform.twitter.com/widgets.jsin the HEAD as a blocking script. - StumbleUpon loads
http://connect.facebook.net/en_US/all.jsat the top of BODY as a blocking script. - NFL loads
http://connect.facebook.net/en_US/all.jsin the HEAD as a blocking script. - Hulu, incredibly, loads Google Analytics in the HEAD as a blocking script. Please use the async snippet!
- Expedia loads
http://connect.facebook.net/en_US/all.jsas a blocking script in the middle of the page, so the right half of the page is blocked from rendering.
These results, although better than I expected, are still alarming. Although I only found five websites with frontend SPOF, that’s 5% of the overall sample. The percentage will likely grow as the sample size grows because best practices are more widely adopted by the top sites. Also, my list of third party hostnames is a small subset of all widgets and analytics available on the Web. And remember, I didn’t even look at ads.
Is it really worth blocking your site’s entire page for a widget button or analytics beacon – especially when workarounds exist? If you’re one of the five sites that faltered above, do yourself and your users a favor and find a way to avoid frontend SPOF. And if you’re outside the top 100, test your site using Pat’s blackhole server by editing /etc/hosts or following Pat’s instructions for testing frontend SPOF on WebPagetest.org.
ControlJS part 3: overriding document.write
This is the third of three blog posts about ControlJS – a JavaScript module for making scripts load faster. The three blog posts describe how ControlJS is used for async loading, delayed execution, and overriding document.write.
The goal of ControlJS is to give developers more control over how JavaScript is loaded. The key insight is to recognize that “loading†has two phases: download (fetching the bytes) and execution (including parsing). In ControlJS part 1 I focused on the download phase using ControlJS to download scripts asynchronously. ControlJS part 2 showed how delaying script execution makes pages load faster, especially for Ajax web apps that download a lot of JavaScript that’s not used immediately. In this post I look at how document.write causes issues when loading scripts asynchronously.
I like ControlJS, but I’ll admit now that I was unable to solve the document.write problem to my satisfaction. Nevertheless, I describe the dent I put in the problem of document.write and point out two alternatives that do a wonderful job of making async work in spite of document.write.
Async and document.write
ControlJS loads scripts asynchronously. By default these async scripts are executed after window onload. If one of these async scripts calls document.write the page is erased. That’s because calling document.write after the document is loaded automatically calls document.open. Anything written to the open document replaces the existing document content. Obviously, this is not the desired behavior.
I wanted ControlJS to work on all scripts in the page. Scripts for ads are notorious for using document.write, but I also found scripts created by website owners that use document.write. I didn’t want those scripts to be inadvertently loaded with ControlJS and have the page get wiped out.
The problem was made slightly easier for me because ControlJS is in control when each inline and external script is being executed. My solution is to override document.write and capture the output for each script one at a time. If there’s no document.write output then proceed to the next script. If there is output then I create an element (for now a SPAN), insert it into the DOM immediately before the SCRIPT tag that’s being executed, and set the SPAN’s innerHTML to the output from document.write.
This works pretty well. I downloaded a local copy of CNN.com and converted it to ControlJS. There were two places where document.write was used (including an ad) and both worked fine. But there are issues. One issue I encountered is that wrapping the output in a SPAN can break certain behavior like hover handlers. But a bigger issue is that browsers ignore “<script…” added via innerHTML, and one of the main ways that ads use document.write is to insert scripts. I have a weak solution to this that parses out the “<script…” HTML and creates a SCRIPT DOM element with the appropriate SRC. It works, but is not very robust.
ControlJS is still valuable even without a robust answer for document.write. You don’t have to convert every script in the page to use ControlJS. If you know an ad or widget uses document.write you can load those scripts the normal way. Or you can test and see how complex the document.write is – perhaps it’s a use cases that ControlJS handles.
Real solutions for async document.write
I can’t end this series of posts without highlighting two alternatives that have solved the asynchronous document.write issue: Aptimize and GhostWriter.
Aptimize sells a web accelerator that changes HTML markup on the fly to have better performance. In September they announced the capability to load scripts asynchronously – including ads. As far as I know this is the first product that offered this feature. I had lunch with Ed and Derek from Aptimize this week and found out more about their implementation. It sounds solid.
Another solution is GhostWriter from Digital Fulcrum. Will contacted me and we had a concall and a few email exchanges about his implementation that uses an HTML parser on the document.write output. You can try the code for free.
Wrapping it up
ControlJS has many features including some that aren’t found in other script loading modules:
- downloads scripts asynchronously
- handles both inline scripts and external scripts
- delays script execution until after the page has rendered
- allows for scripts to be downloaded and not executed
- integrates with simple changes to HTML – no code changes
- solves some document.write async use cases
- control.js itself is loaded asynchronously
ControlJS is open source. I hope some of these features are borrowed and added to other script loaders. There’s still more features to implement (async stylesheets, better document.write handling) and ControlJS has had minimal testing. If you’d like to add features or fix bugs please take a look at the ControlJS project on Google Code and contact the group via the ControlJS discussion list.
ControlJS part 2: delayed execution
This is the second of three blog posts about ControlJS – a JavaScript module for making scripts load faster. The three blog posts describe how ControlJS is used for async loading, delayed execution, and overriding document.write.
The goal of ControlJS is to give developers more control over how JavaScript is loaded. The key insight is to recognize that “loading†has two phases: download (fetching the bytes) and execution (including parsing). In ControlJS part 1 I focused on the download phase using ControlJS to download scripts asynchronously. In this post I focus on the benefits ControlJS brings to the execution phase of script loading.
The issue with execution
The issue with the execution phase is that while the browser is parsing and executing JavaScript it can’t do much else. From a performance perspective this means the browser UI is unresponsive, page rendering stops, and the browser won’t start any new downloads.
The execution phase can take more time than you might think. I don’t have hard numbers on how much time is spent in this phase (although it wouldn’t be that hard to collect this data with dynaTrace Ajax Edition or Speed Tracer). If you do anything computationally intensive with a lot of DOM interaction the blocking effects can be noticeable. If you have a large amount of JavaScript just parsing the code can take a significant amount of time.
If all the JavaScript was used immediately to render the page we might have to throw up our hands and endure these delays, but it turns out that a lot of the JavaScript downloaded isn’t used right away. Across the Alexa US Top 10 only 29% of the downloaded JavaScript is called before the window load event. (I surveyed this using Page Speed‘s “defer JavaScript” feature.) The other 71% of the code is parsed and executed even though it’s not used for rendering the initial page. For these pages an average of 229 kB of JavaScript is downloaded. That 229 kB is compressed – the uncompressed size is upwards of 500 kB. That’s a lot of JavaScript. Rather than parse and execute 71% of the JavaScript in the middle of page loading, it would be better to avoid that pain until after the page is done rendering. But how can a developer do that?
Loading feature code
To ease our discussion let’s call that 29% of code used to render the page immediate-code and we’ll call the other 71% feature-code. The feature-code is typically for DHTML and Ajax features such as drop down menus, popup dialogs, and friend requests where the code is only executed if the user exercises the feature. (That’s why it’s not showing up in the list of functions called before window onload.)
Let’s assume you’ve successfully split your JavaScript into immediate-code and feature-code. The immediate-code scripts are loaded as part of the initial page loading process using ControlJS’s async loading capabilities. The additional scripts that contain the feature-code could also be loaded this way during the initial page load process, but then the browser is going to lock up parsing and executing code that’s not immediately needed. So we don’t want to load the feature-code during the initial page loading process.
Another approach would be to load the feature-code after the initial page is fully rendered. The scripts could be loaded in the background as part of an onload handler. But even though the feature-code scripts are downloaded in the background, the browser still locks up when it parses and executes them. If the user tries to interact with the page the UI is unresponsive. This unnecessary delay is painful enough that the Gmail mobile team went out of their way to avoid it. To make matters worse, the user has no idea why this is happening since they didn’t do anything to cause the lock up. (We kicked it off “in the background”.)
The solution is to parse and execute this feature-code when the user needs it. For example, when the user first clicks on the drop down menu is when we parse and execute menu.js. If the user never uses the drop down menu, then we avoid the cost of parsing and executing that code altogether. But when the user clicks on that menu we don’t want her to wait for the bytes to be downloaded – that would take too long especially on mobile. The best solution is to download the script in the background but delay execution until later when the code is actually needed.
Download now, Execute later
After that lengthy setup we’re ready to look at the delayed execution capabilities of ControlJS. I created an example that has a drop down menu containing the links to the examples.

In order to illustrate the pain from lengthy script execution I added a 2 second delay to the menu code (a while loop that doesn’t relinquish until 2 seconds have passed). Menu withOUT ControlJS is the baseline case. The page takes a long time to render because it’s blocked while the scripts are downloaded and also during the 2 seconds of script execution.
On the other hand, Menu WITH ControlJS renders much more quickly. The scripts are downloaded asynchronously. Since these scripts are for an optional feature we want to avoid executing them until later. This is achieved by using the “data-cjsexec=false” attribute, in addition to the other ControlJS modifications to the SCRIPT’s TYPE and SRC attributes:
<script data-cjsexec=false type="text/cjs" data-cjssrc="jquery.min.js"></script> <script data-cjsexec=false type="text/cjs" data-cjssrc="fg.menu.js"></script>
The “data-cjsexec=false” setting means that the scripts are downloaded and stored in the cache, but they’re not executed. The execution is triggered later if and when the user exercises the feature. In this case, clicking on the Examples button is the trigger:
examplesbtn.onclick = function() {
CJS.execScript("jquery.min.js");
CJS.execScript("fg.menu.js", createExamplesMenu);
};
CJS.execScript() creates a SCRIPT element with the specified SRC and inserts it into the DOM. The menu creation function, createExamplesMenu, is passed in as the onload callback function for the last script. The 2 second delay is therefore incurred the first time the user clicks on the menu, but it’s tied to a the user’s action, there’s no delay to download the script, and the execution delay only occurs once.
The ability to separate and control the download phase and the execution phase during script loading is a key differentiator of ControlJS. Many websites won’t need this option. But websites that have a lot of code that’s not used to render the initial page, such as Ajax web apps, will benefit from avoiding the pain of script parsing and execution until it’s absolutely necessary.